Energy-based Models are Zero-Shot Planners for Compositional Scene Rearrangement
Abstract
Language is compositional; an instruction can express multiple relation constraints to hold among objects in a scene that a robot is tasked to rearrange. Our focus in this work is an instructable scene-rearranging framework that generalizes to longer instructions and to spatial concept compositions never seen at training time. We propose to represent language-instructed spatial concepts with energy functions over relative object arrangements. A language parser maps instructions to corresponding energy functions and an open-vocabulary visual-language model grounds their arguments to relevant objects in the scene. We generate goal scene configurations by gradient descent on the sum of energy functions, one per language predicate in the instruction. Local vision-based policies then re-locate objects to the inferred goal locations. We test our model on established instruction-guided manipulation benchmarks, as well as benchmarks of compositional instructions we introduce. We show our model can execute highly compositional instructions zero-shot in simulation and in the real world. It outperforms language-to-action reactive policies and Large Language Model planners by a large margin, especially for long instructions that involve compositions of multiple spatial concepts.
Method
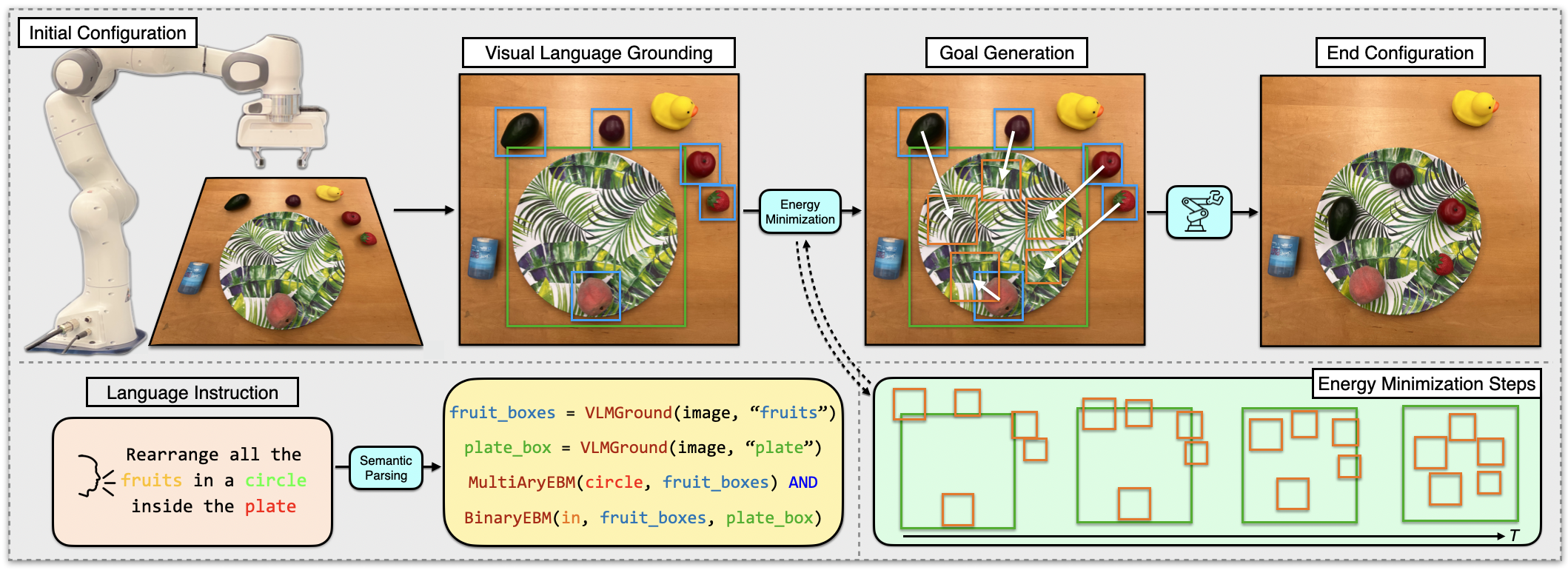
Given an image and a language instruction, a semantic parser maps the language into a set of energy functions (BinaryEBM, MultiAryEBM), one for each spatial predicate in the instruction, and calls to an open-vocabulary visual language grounder (VLMGround) to localize the object arguments of each energy function mentioned in the instruction, here "fruits" and "plate". Gradient descent on the sum of energy functions with respect to object spatial coordinates generates the goal scene configuration. Vision-based neural policies condition on the predicted pick and place visual image crops and predict accurate pick and place locations to manipulate the objects.
Real-world Results
Our model is trained in simulation and can generalize to the real world without any real-world training or adaptation thanks to the open-vocabulary detector trained on real-world images, as well as the object abstractions in the predicate EBMs and low-level policy modules. In addition to robot execution, we also show all intermediate visual grounding outputs and energy minimization for goal generation.
Simulation Results
Videos 1-4 (left to right) demonstrate our zero-shot generalization to compositions of known concepts. Videos 5 and 6 show multi-ary concepts. Videos 7 and 8 showcase closed-loop execution. Our model fails to solve the task in the first attempt, but then re-detects the referred objects, compares their location to the goal location (the output of the EBM planner) and re-locates them to complete the task.
Examples of Energy Optimization
(Left to right) Examples 1-5 show training concepts, both binary and multi-ary. Examples 6-8 show zero-shot generalization to compositions of training concepts. Example 9 shows a task that involves pose optimization. Examples 10 and 11 display our EBMs' ability to learn 3D concepts and generalize zero-shot to compositions of them.
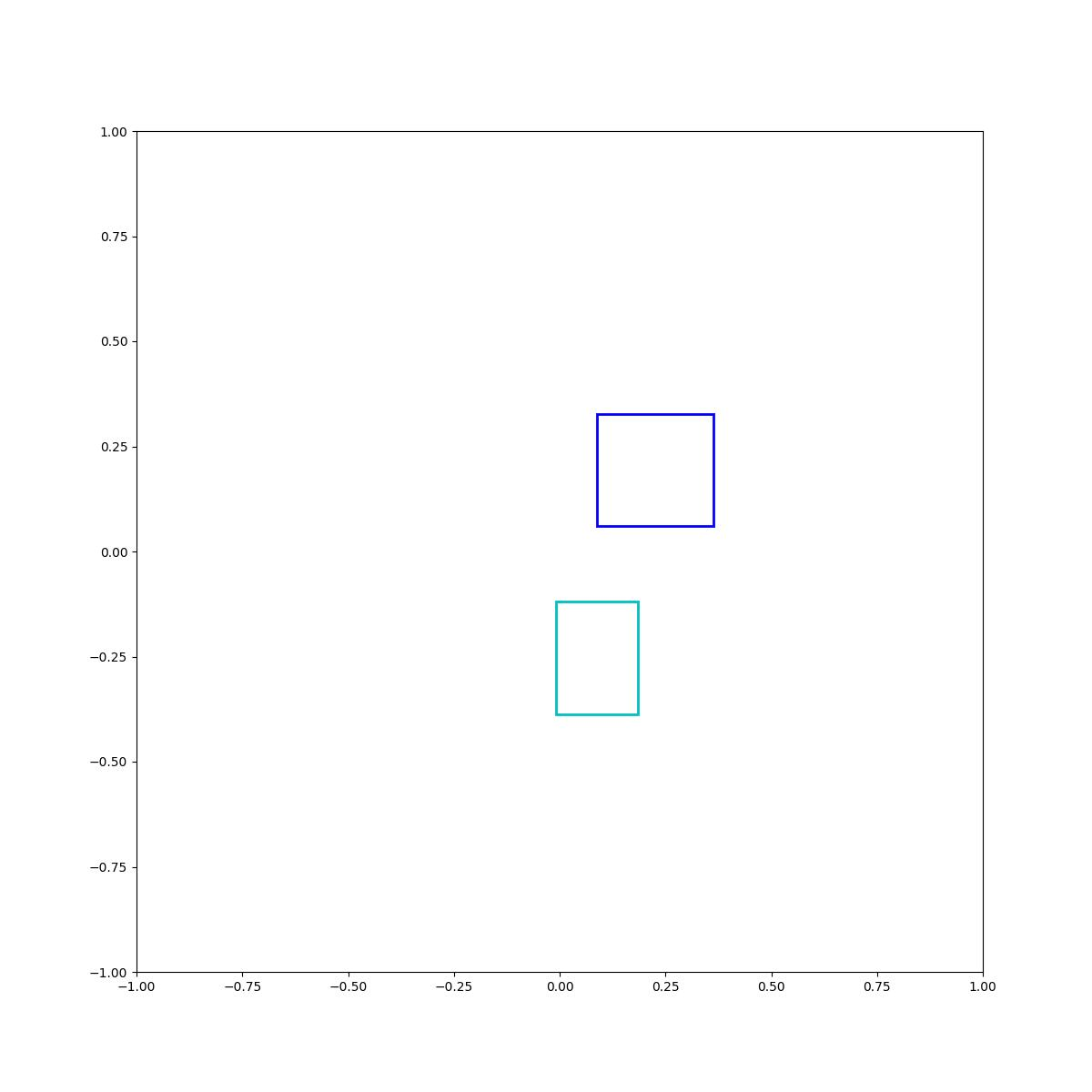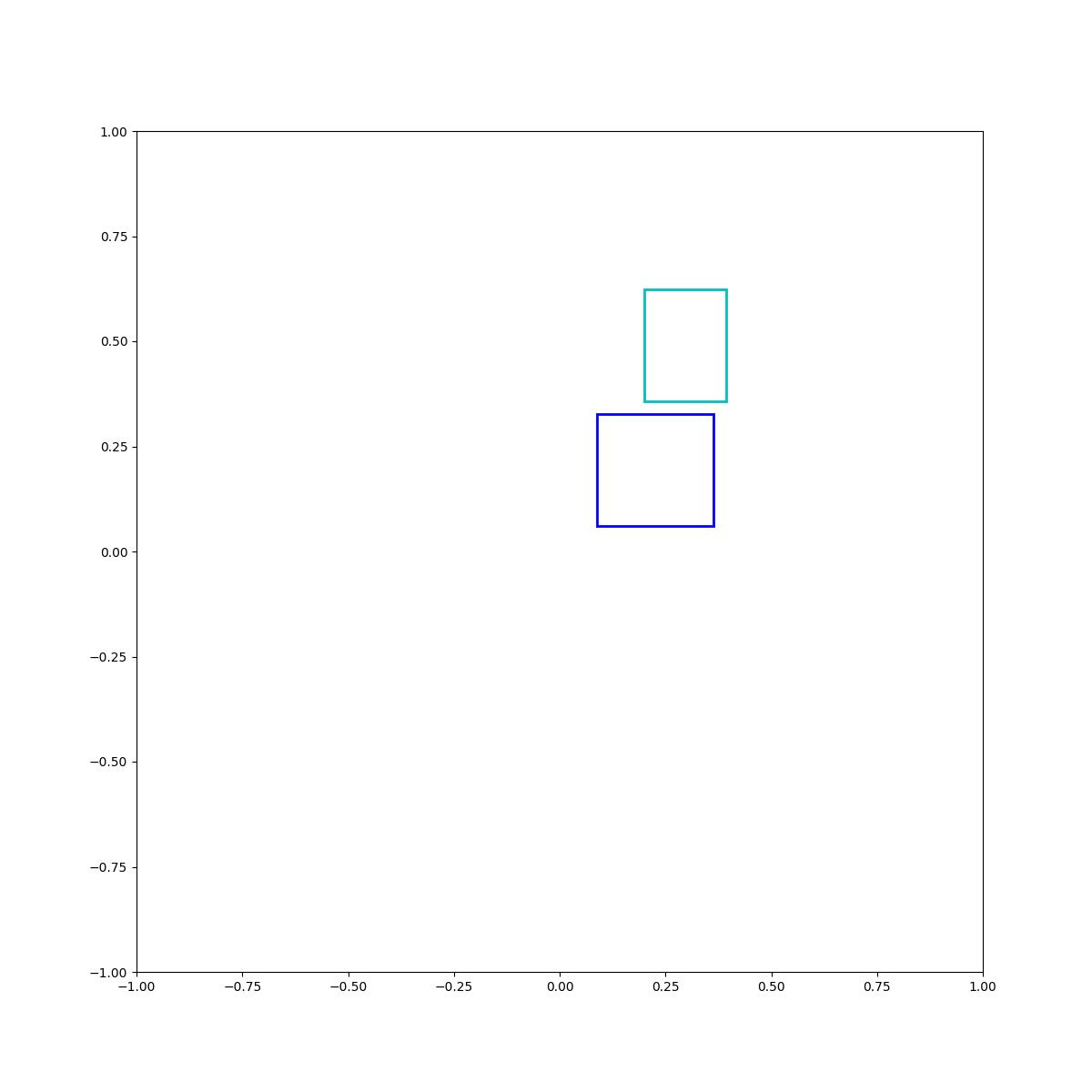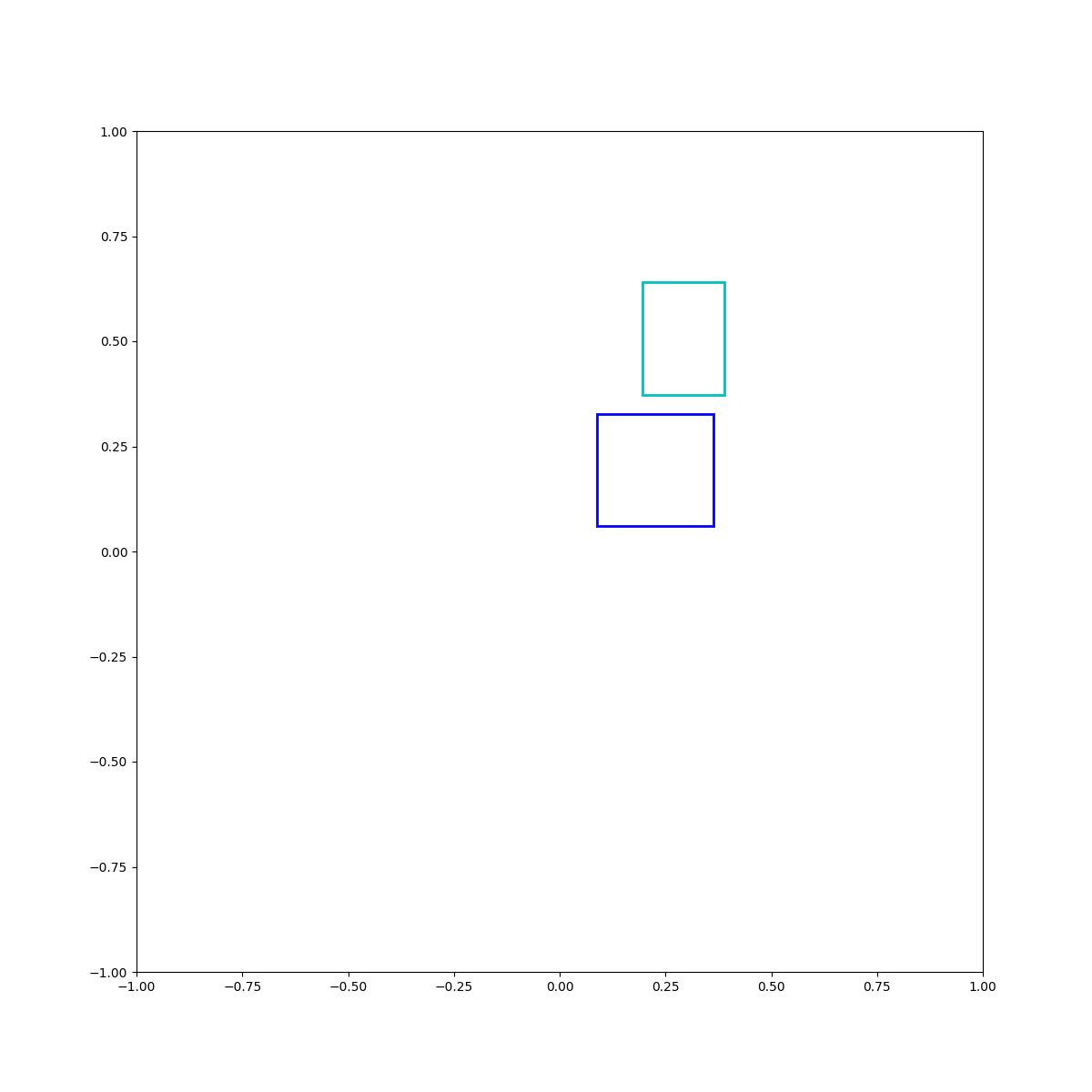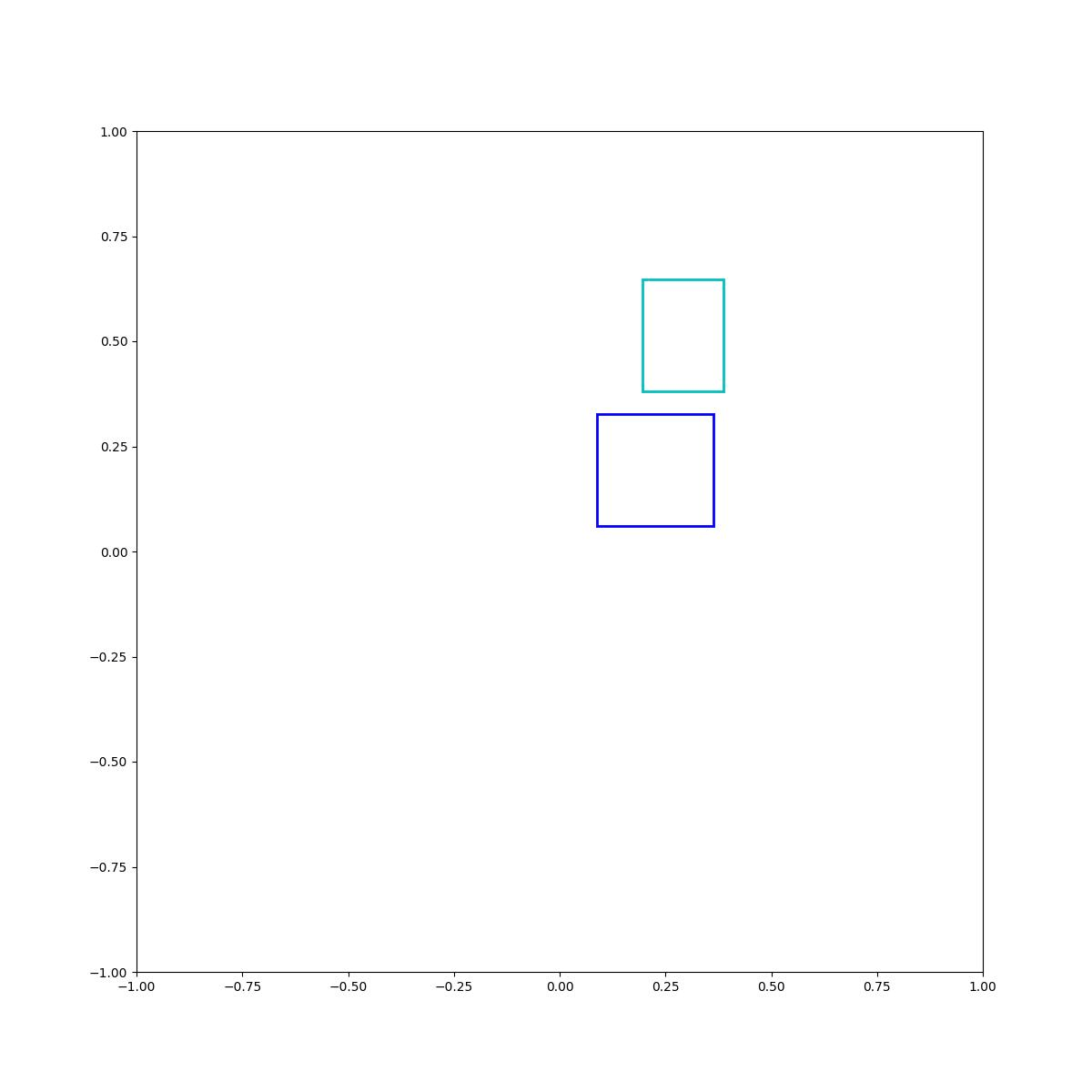
Cyan above blue
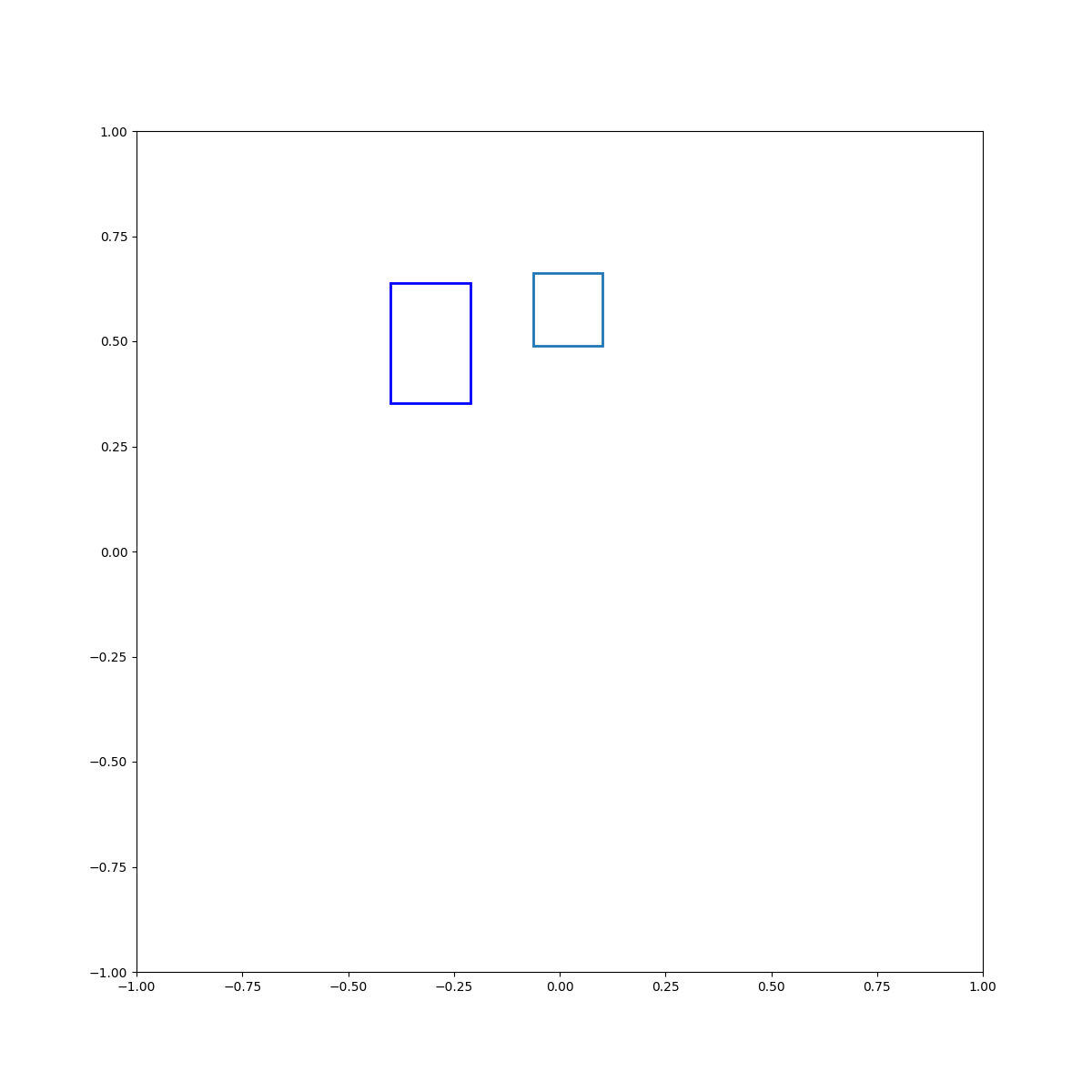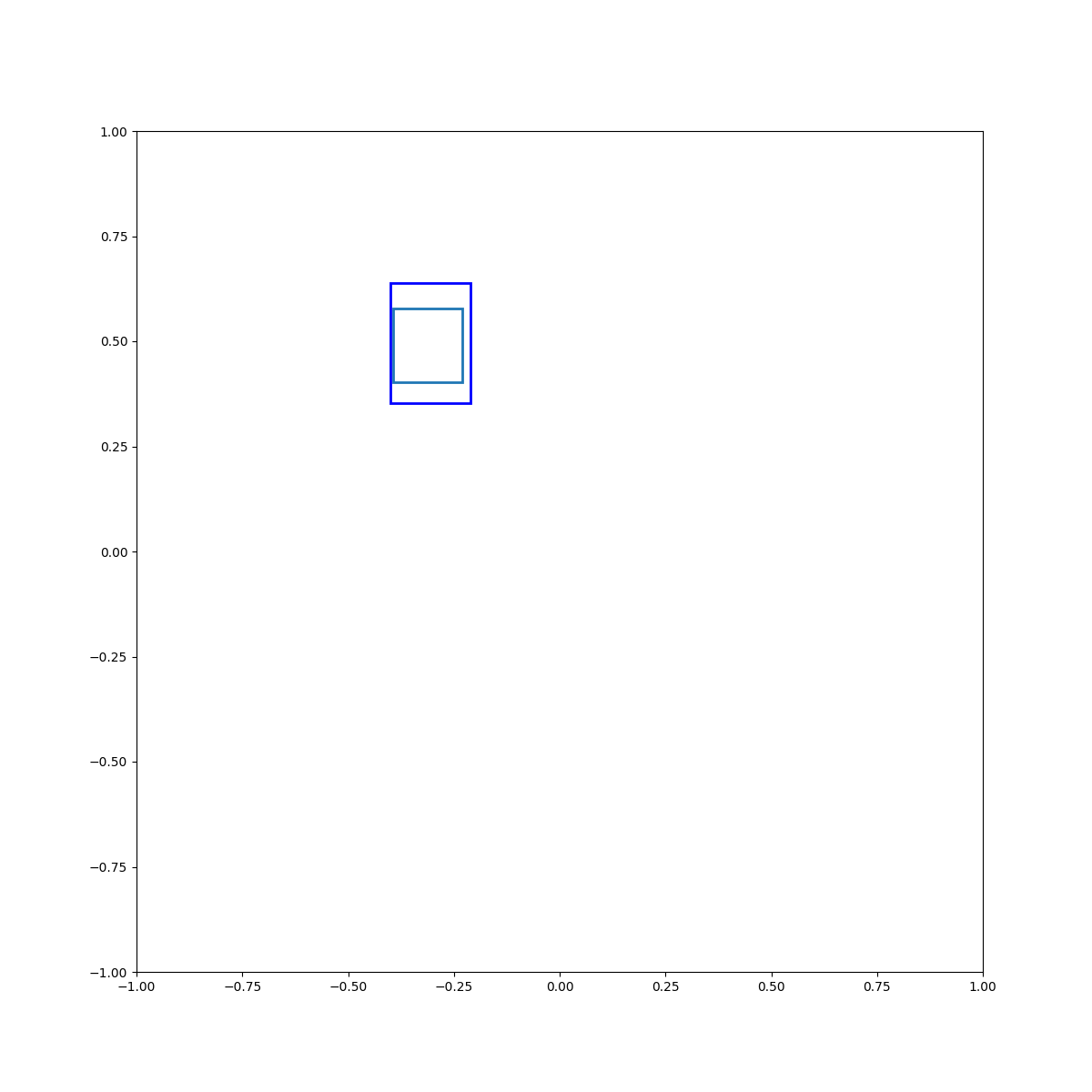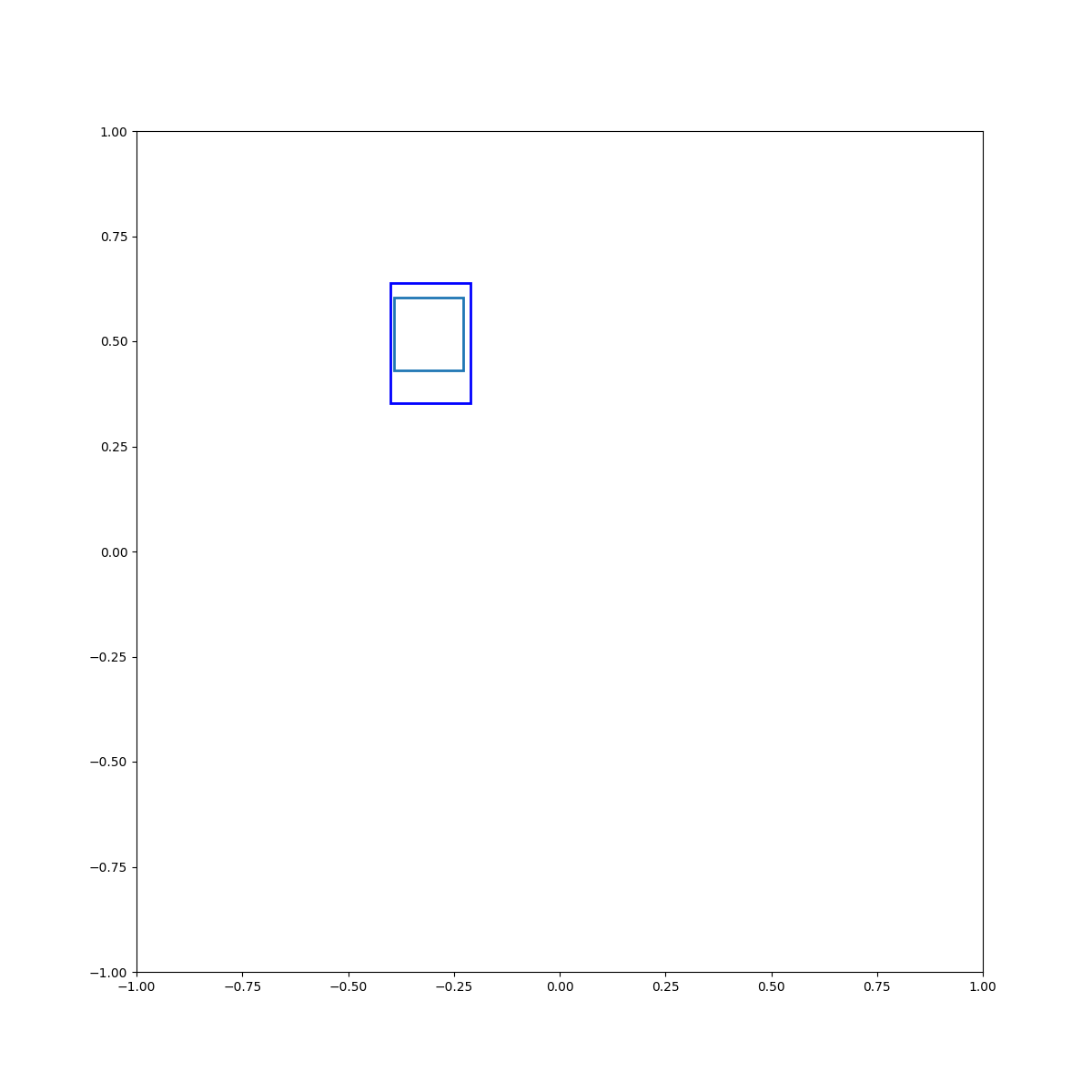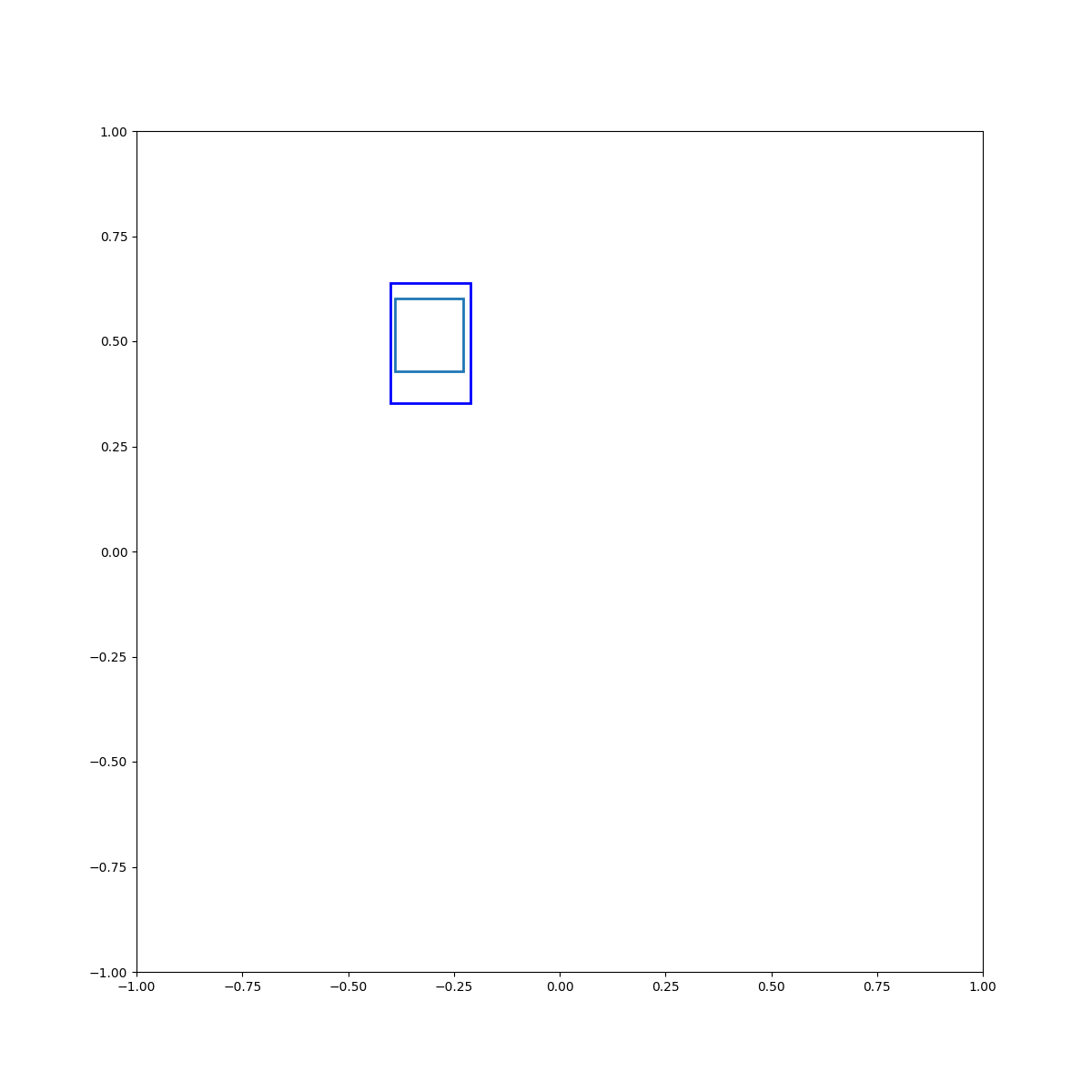
Cyan inside blue
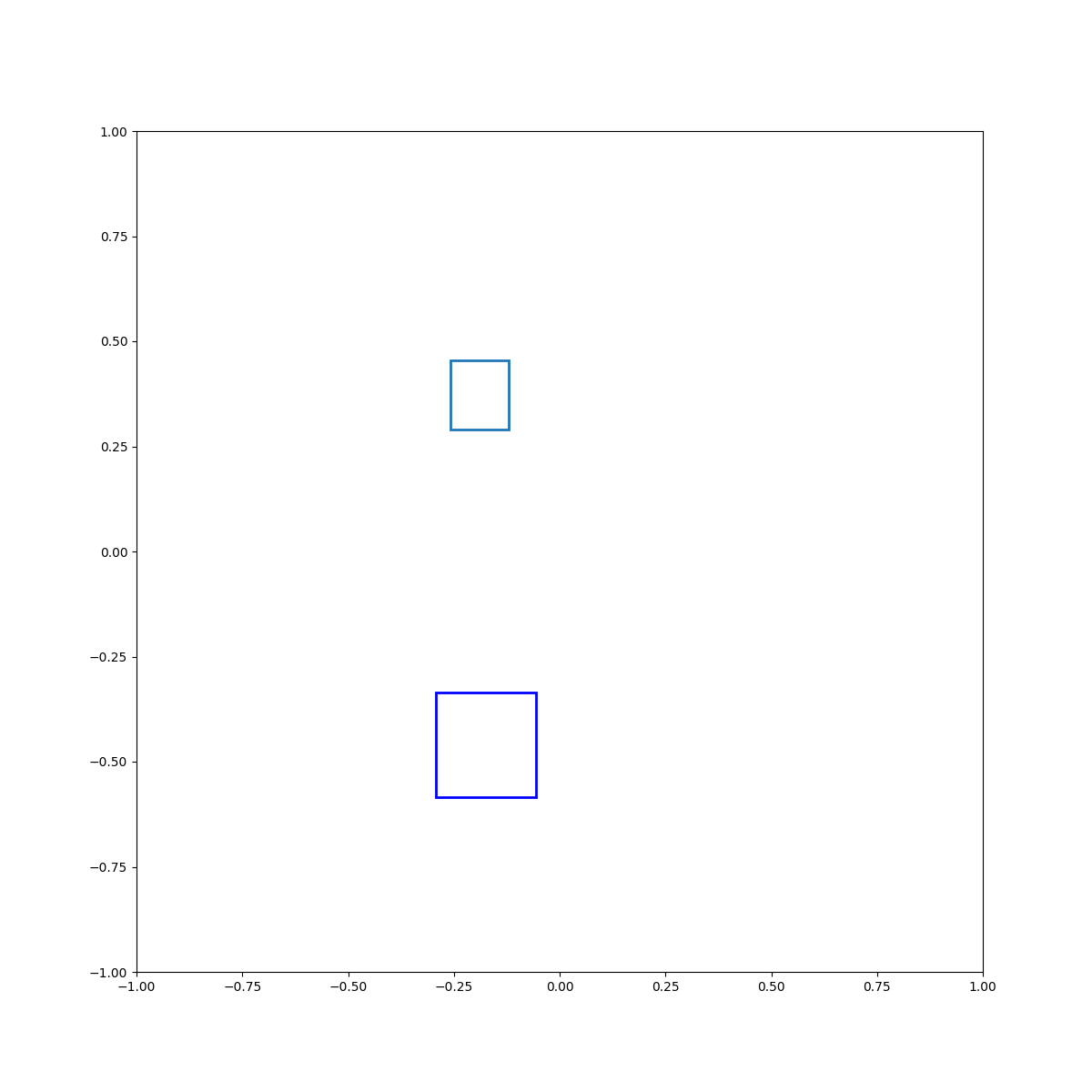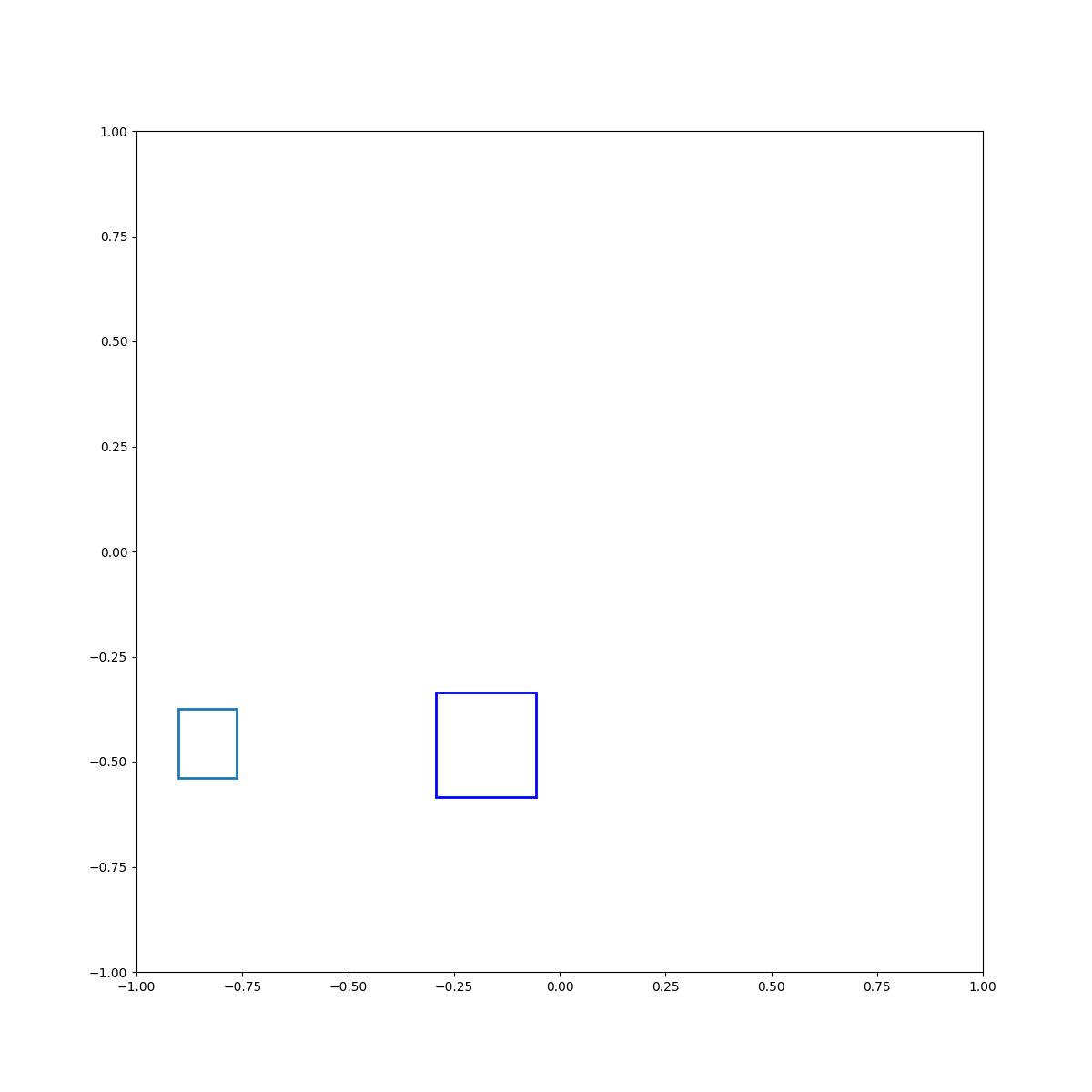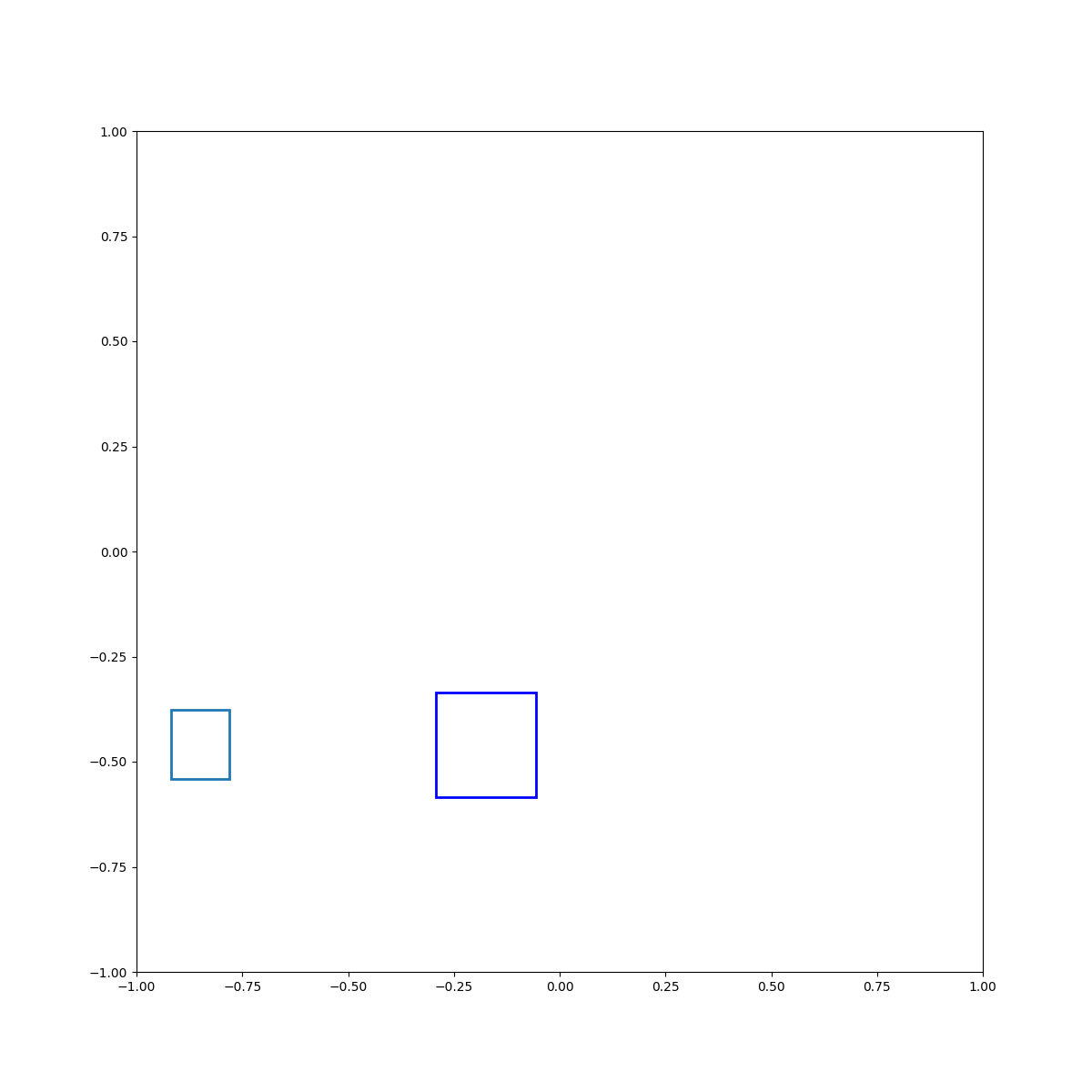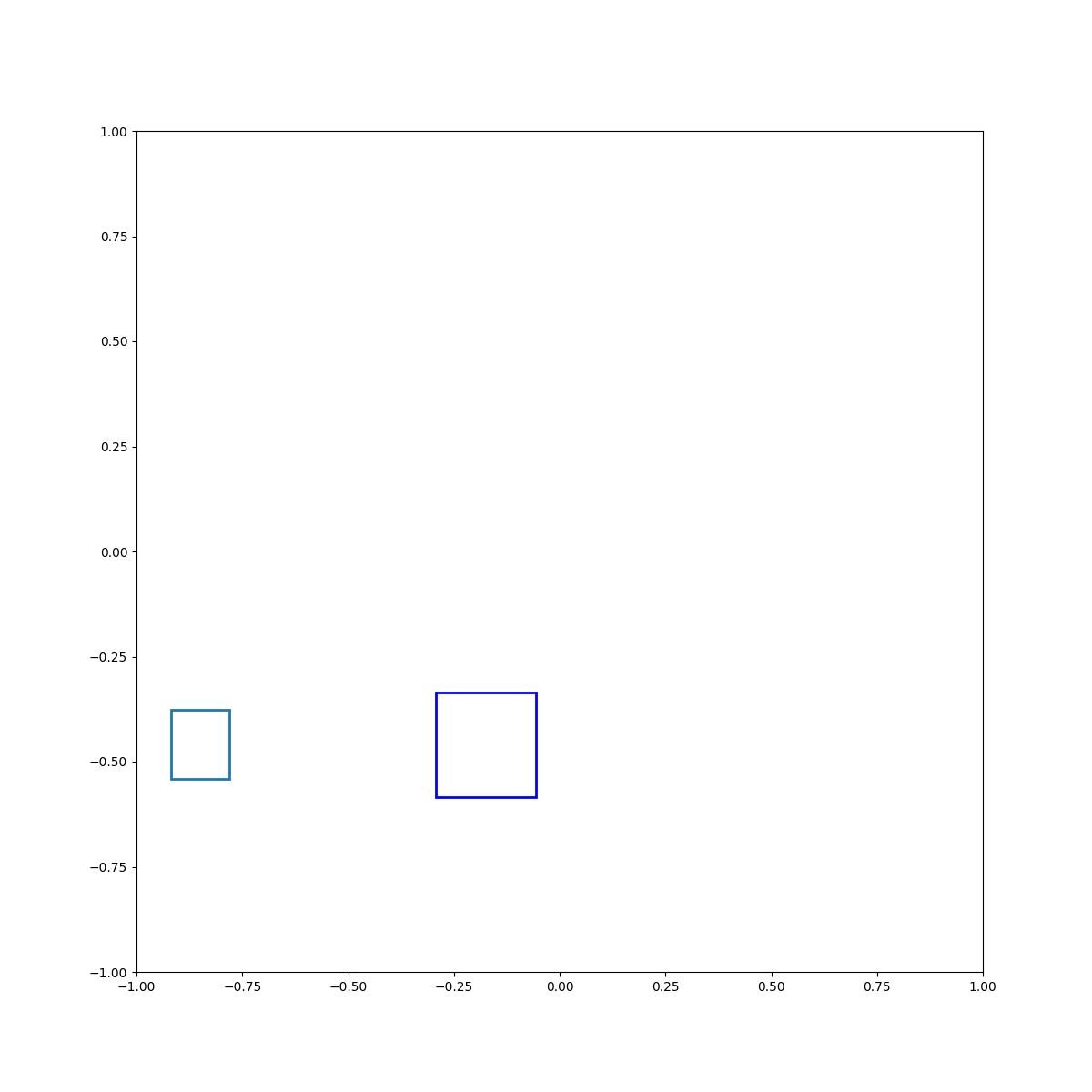
Cyan left of blue
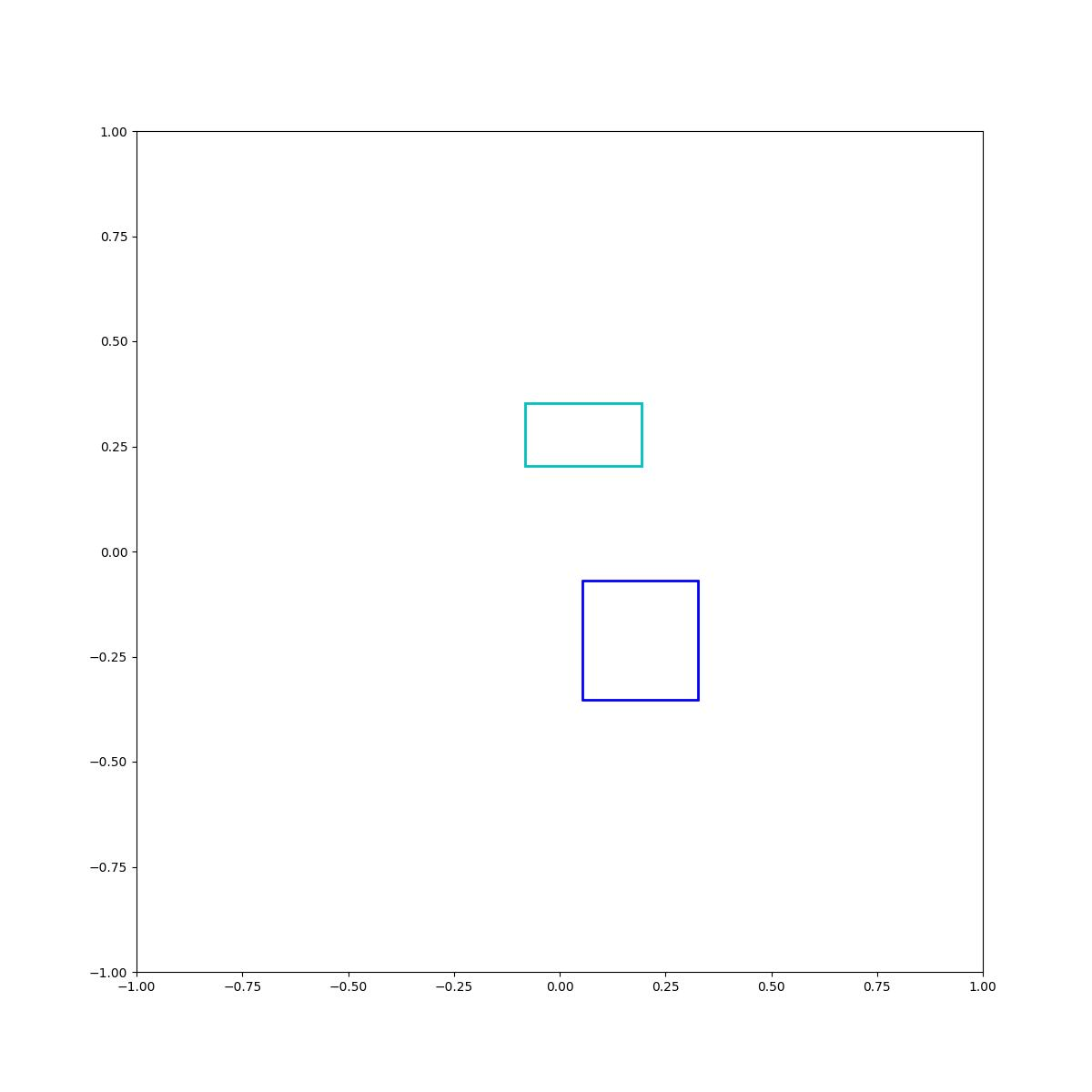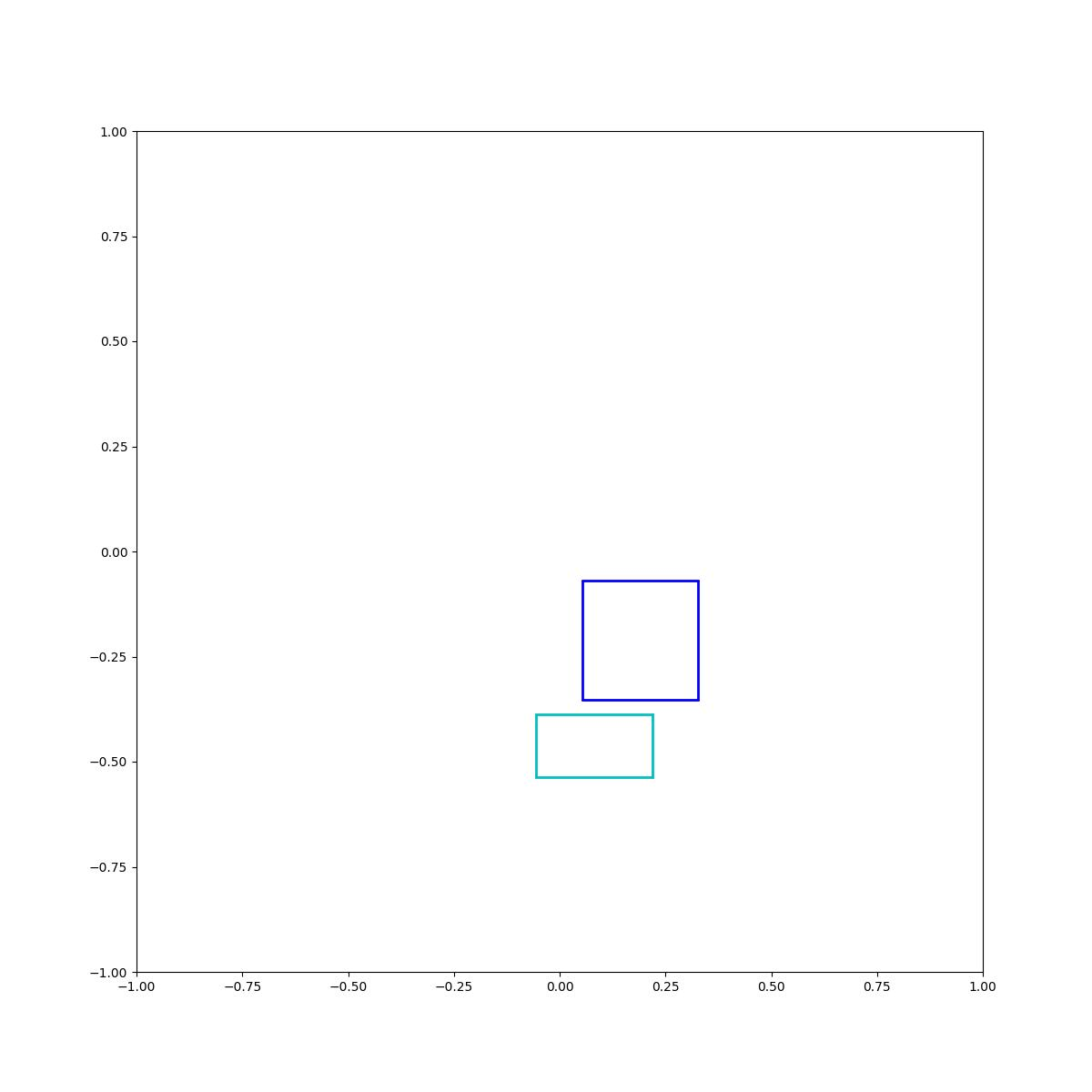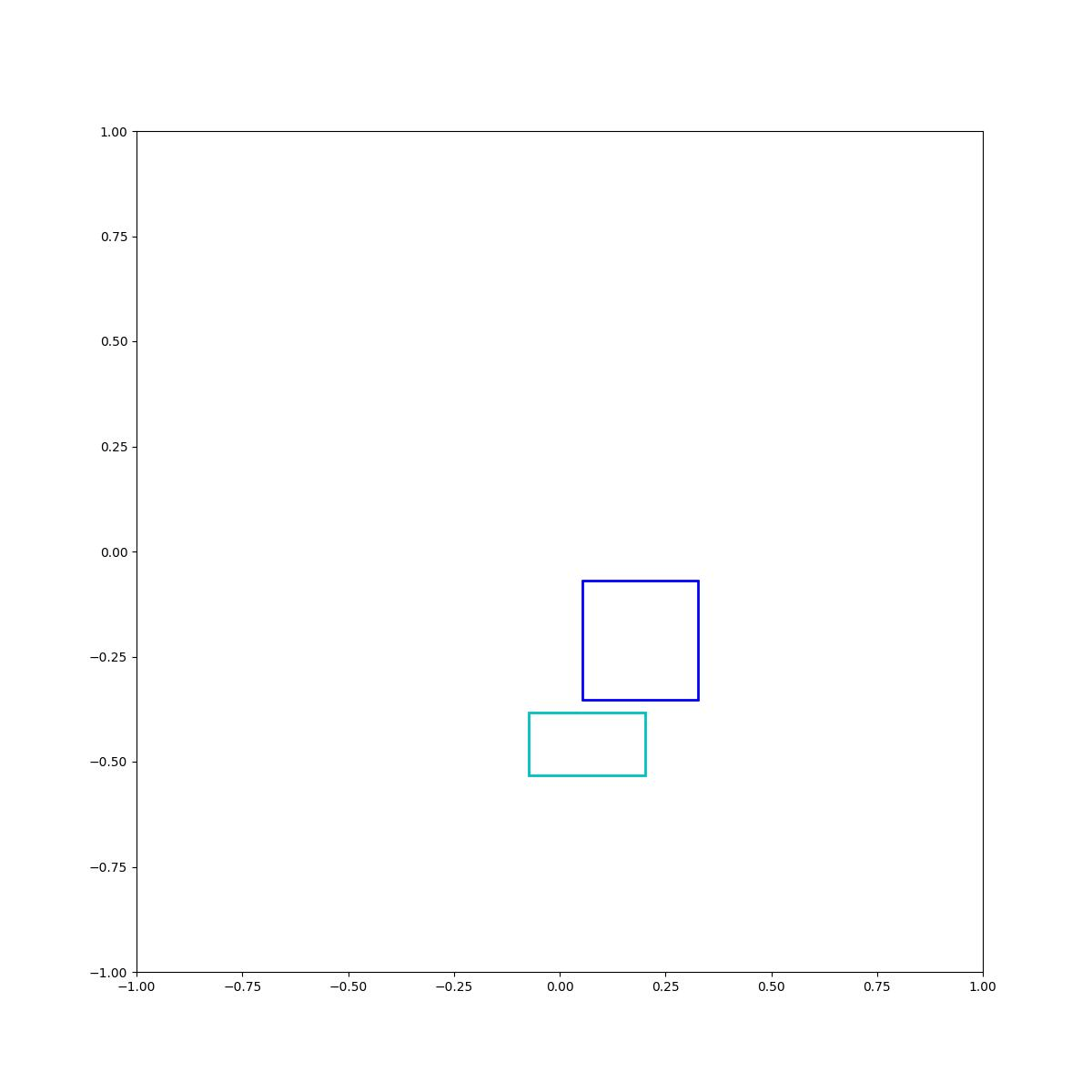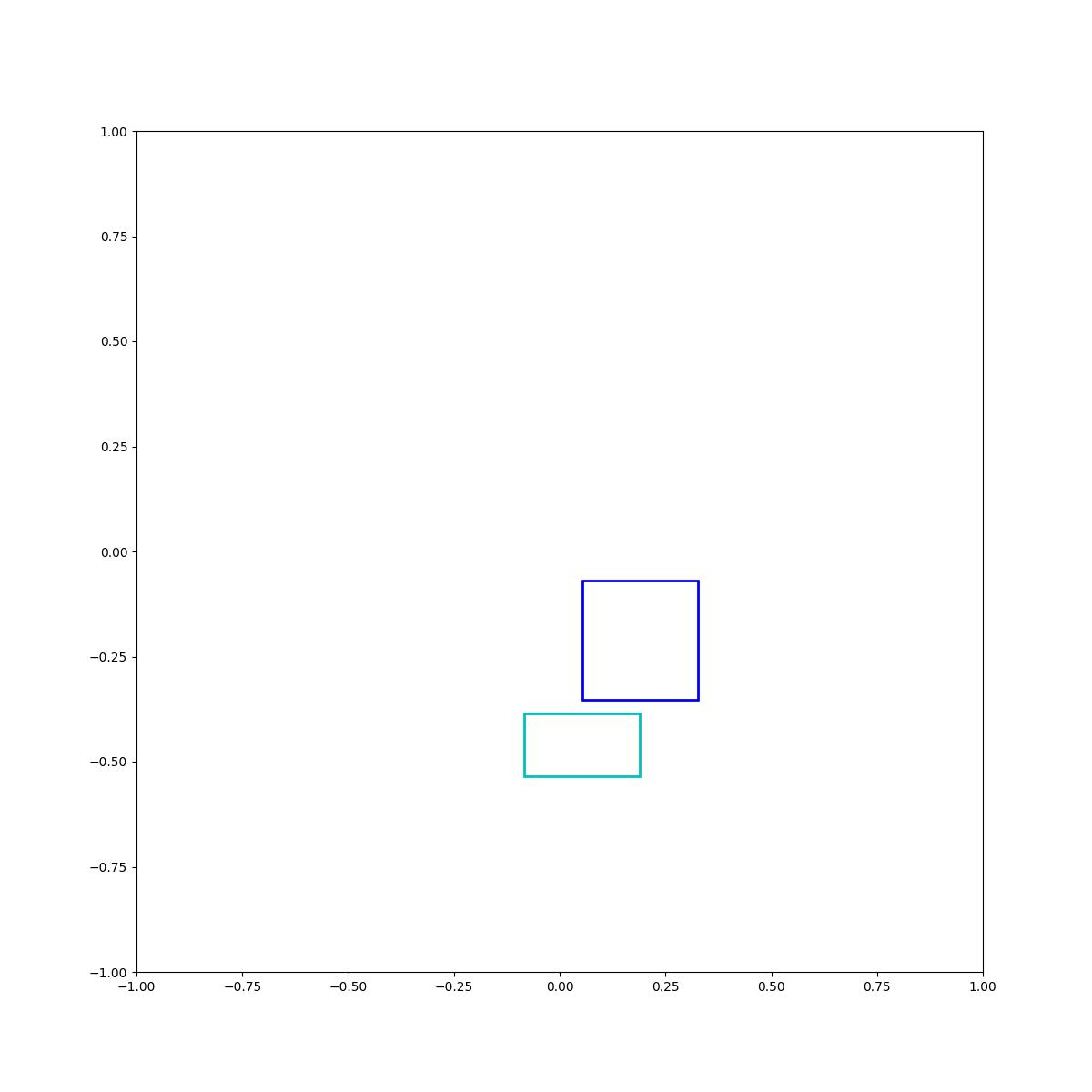
Cyan below blue
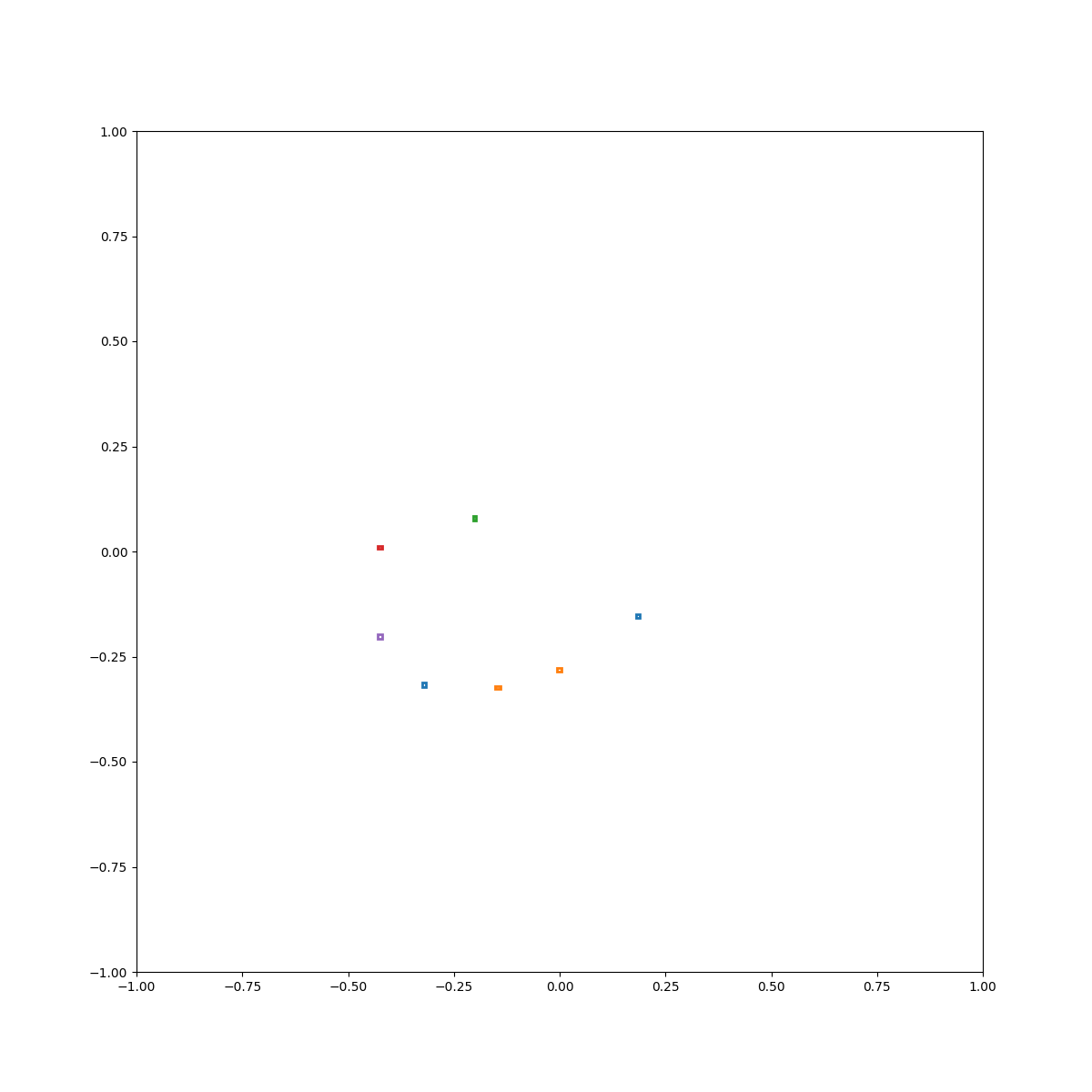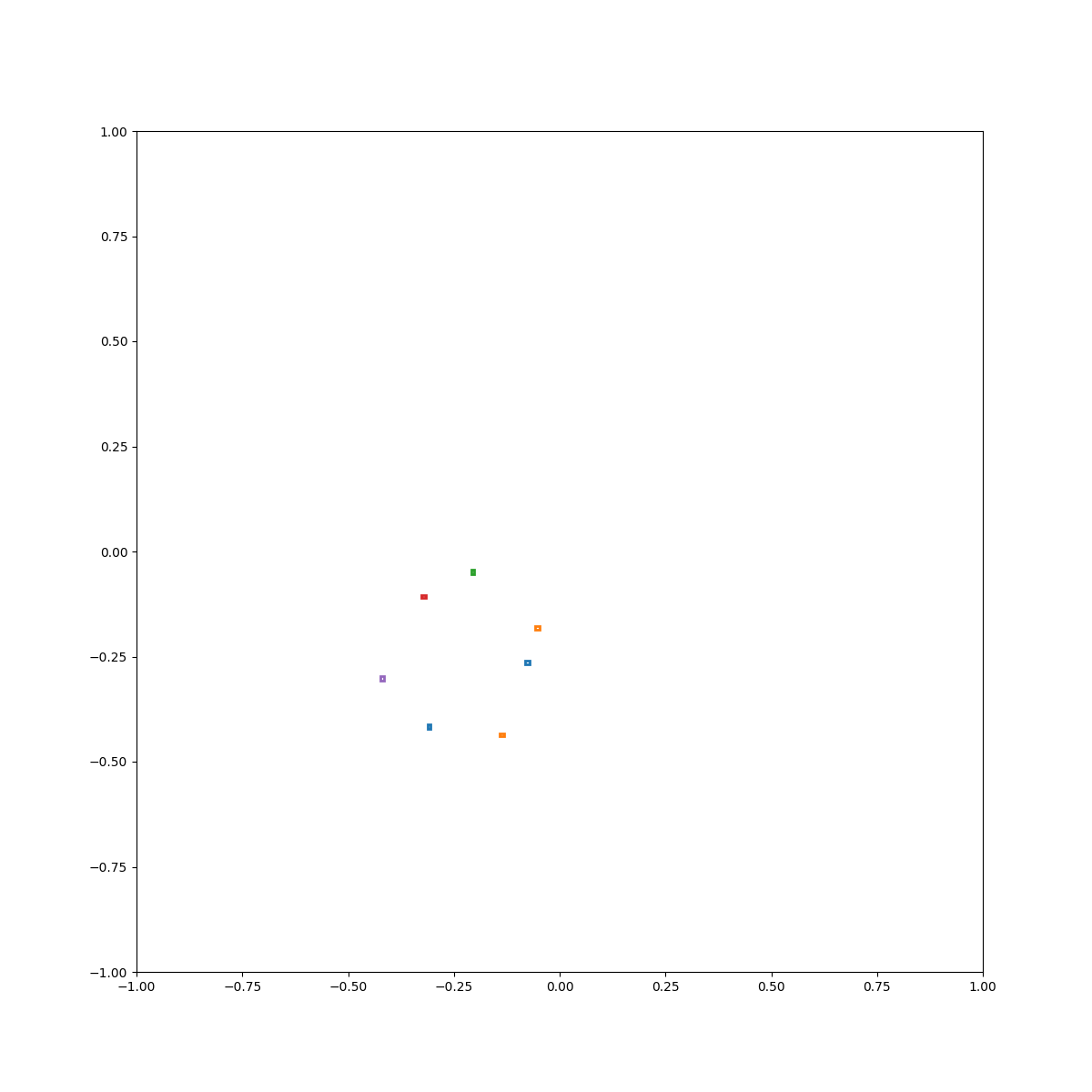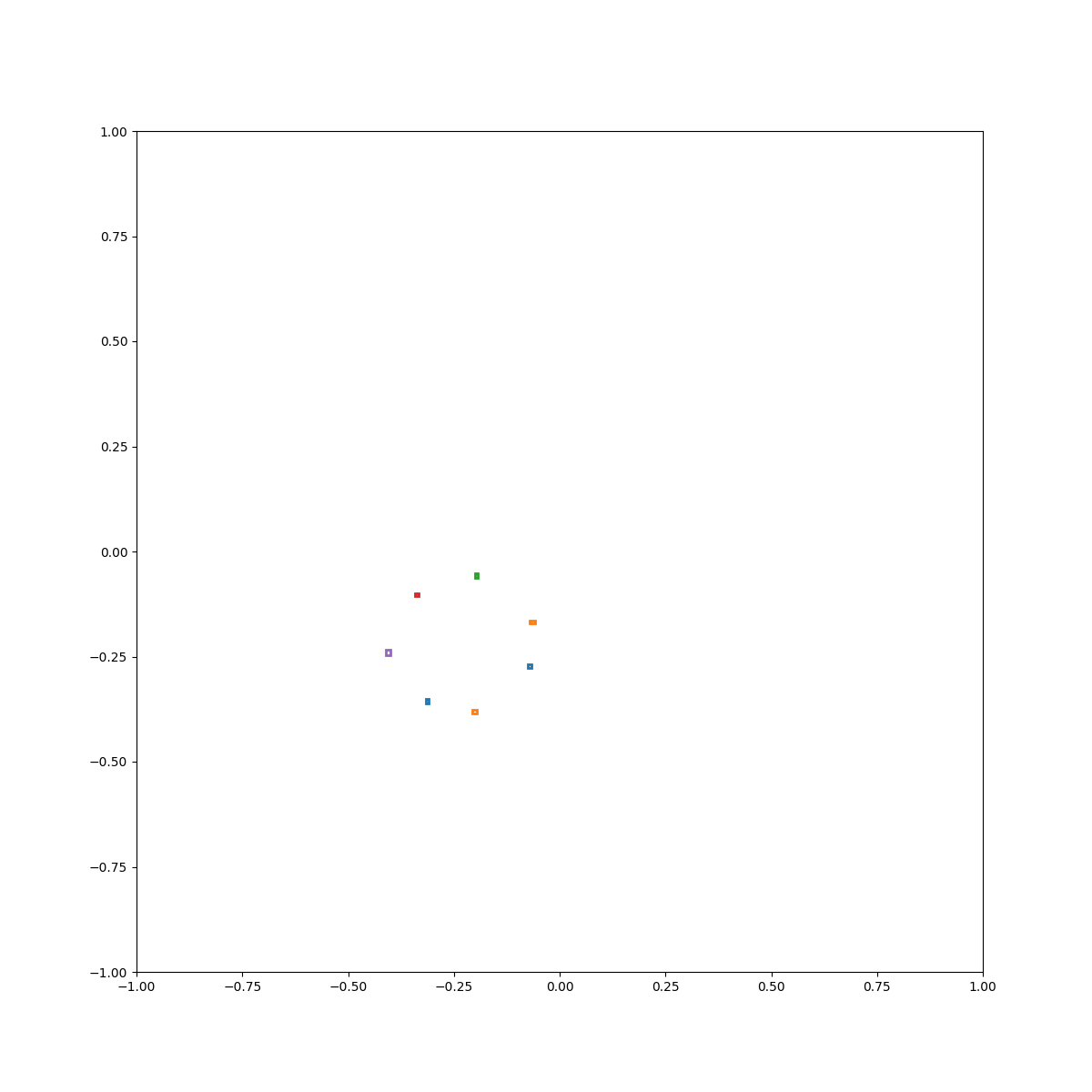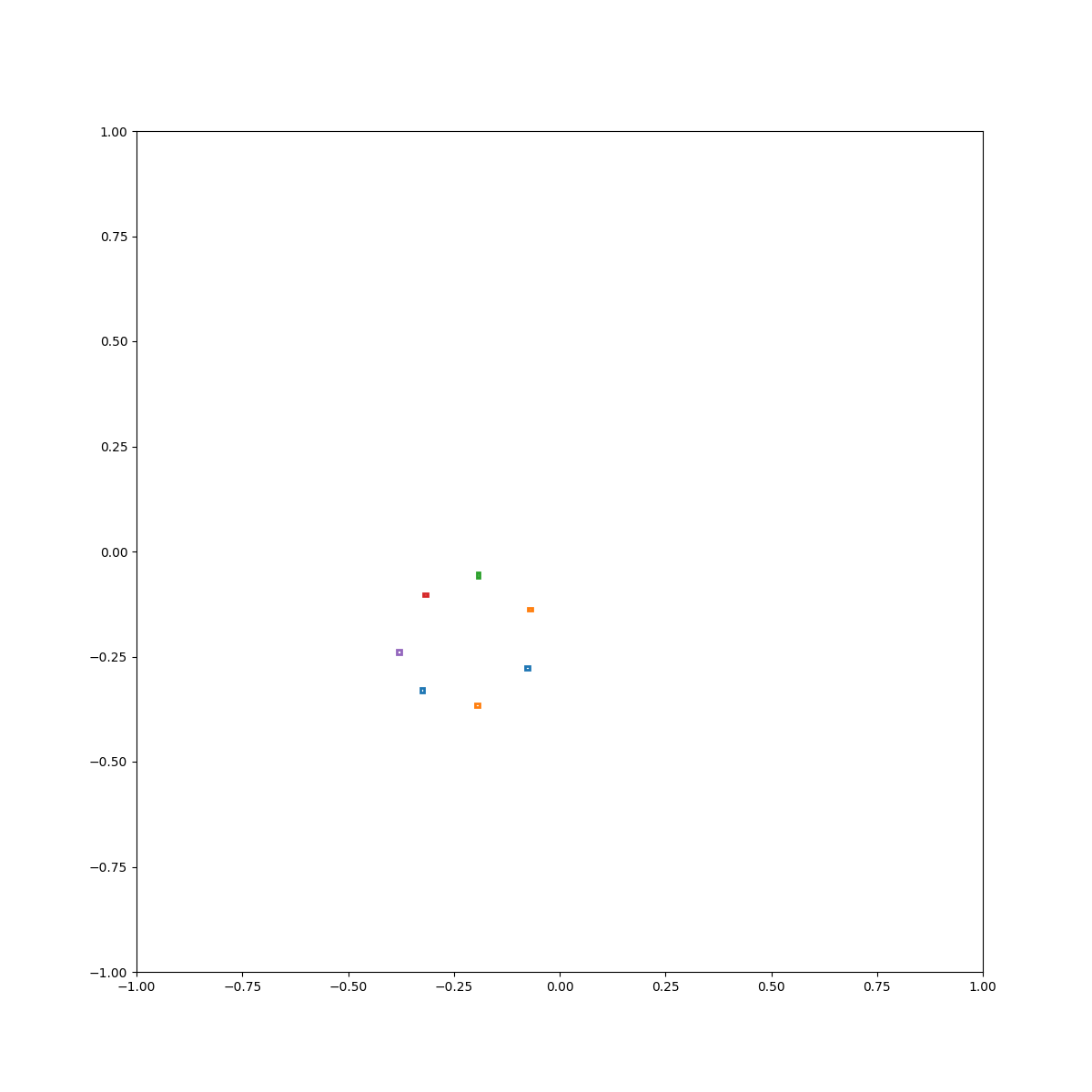
Circle
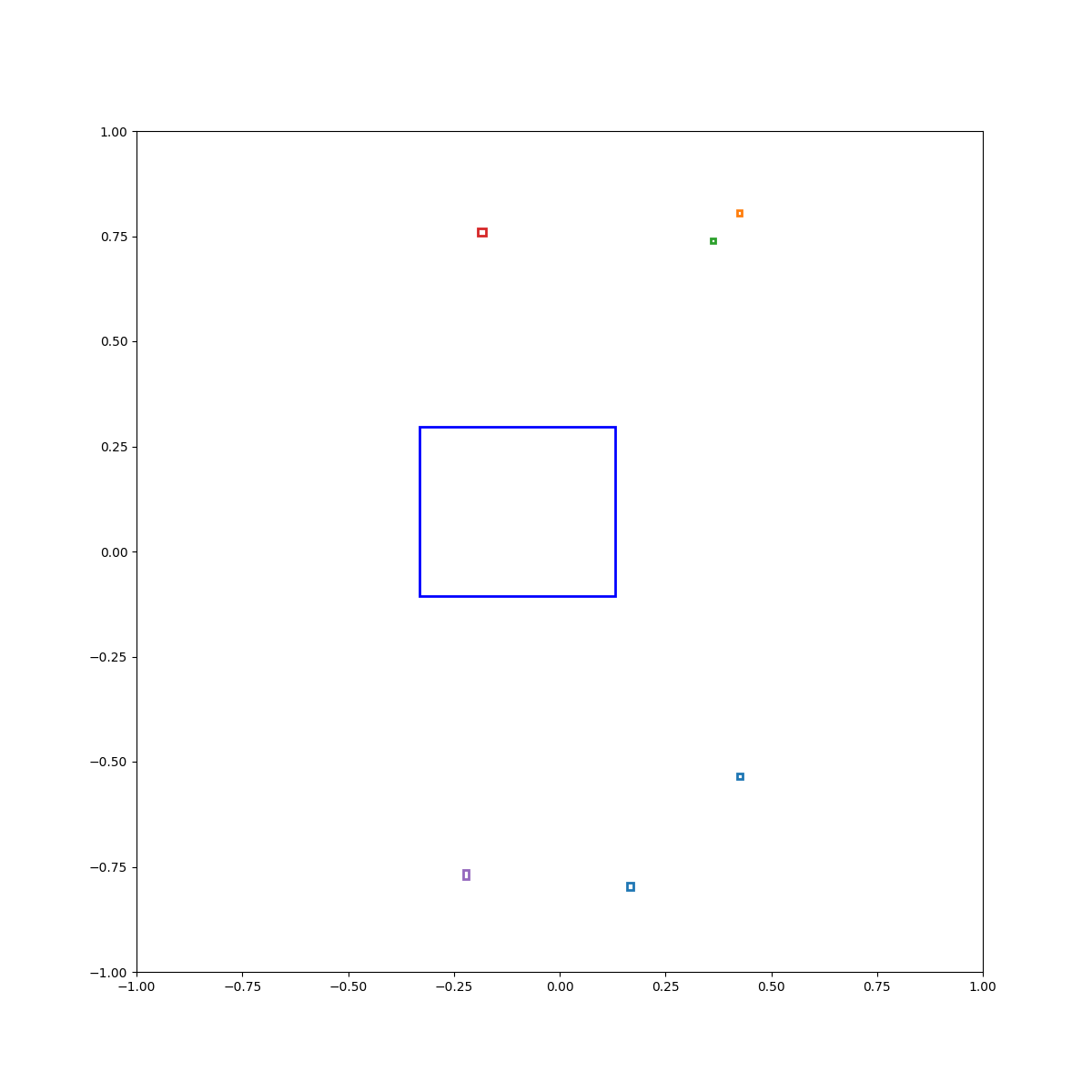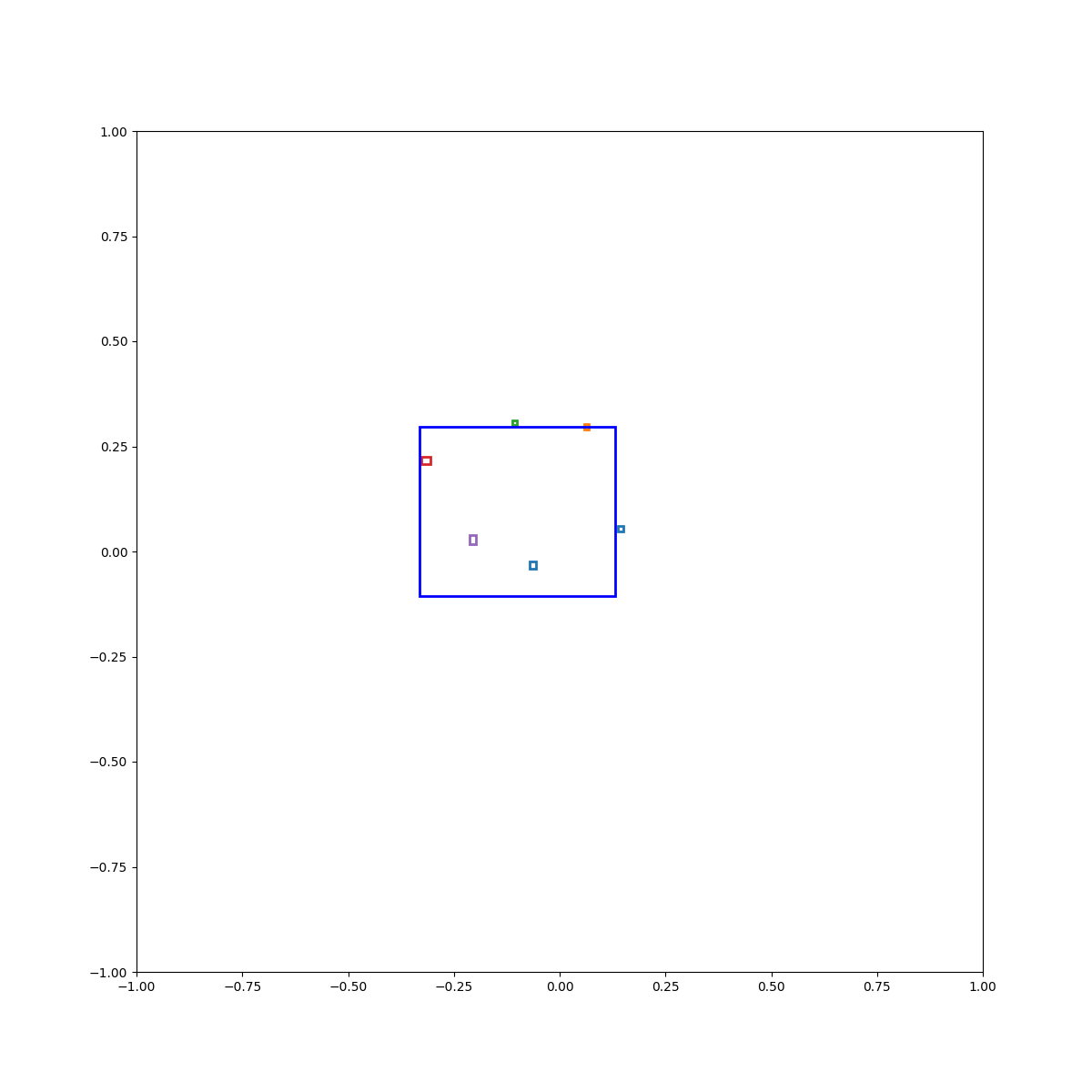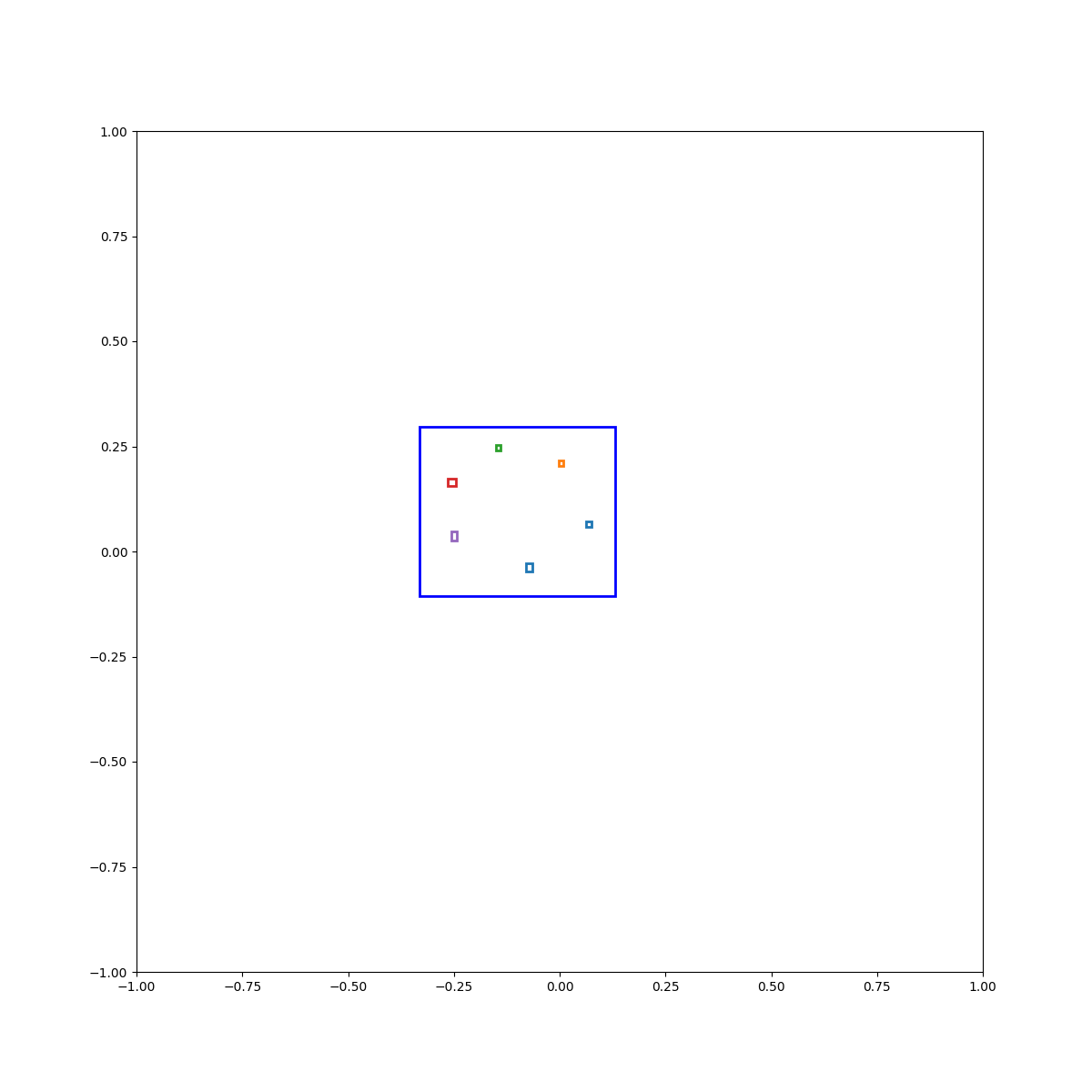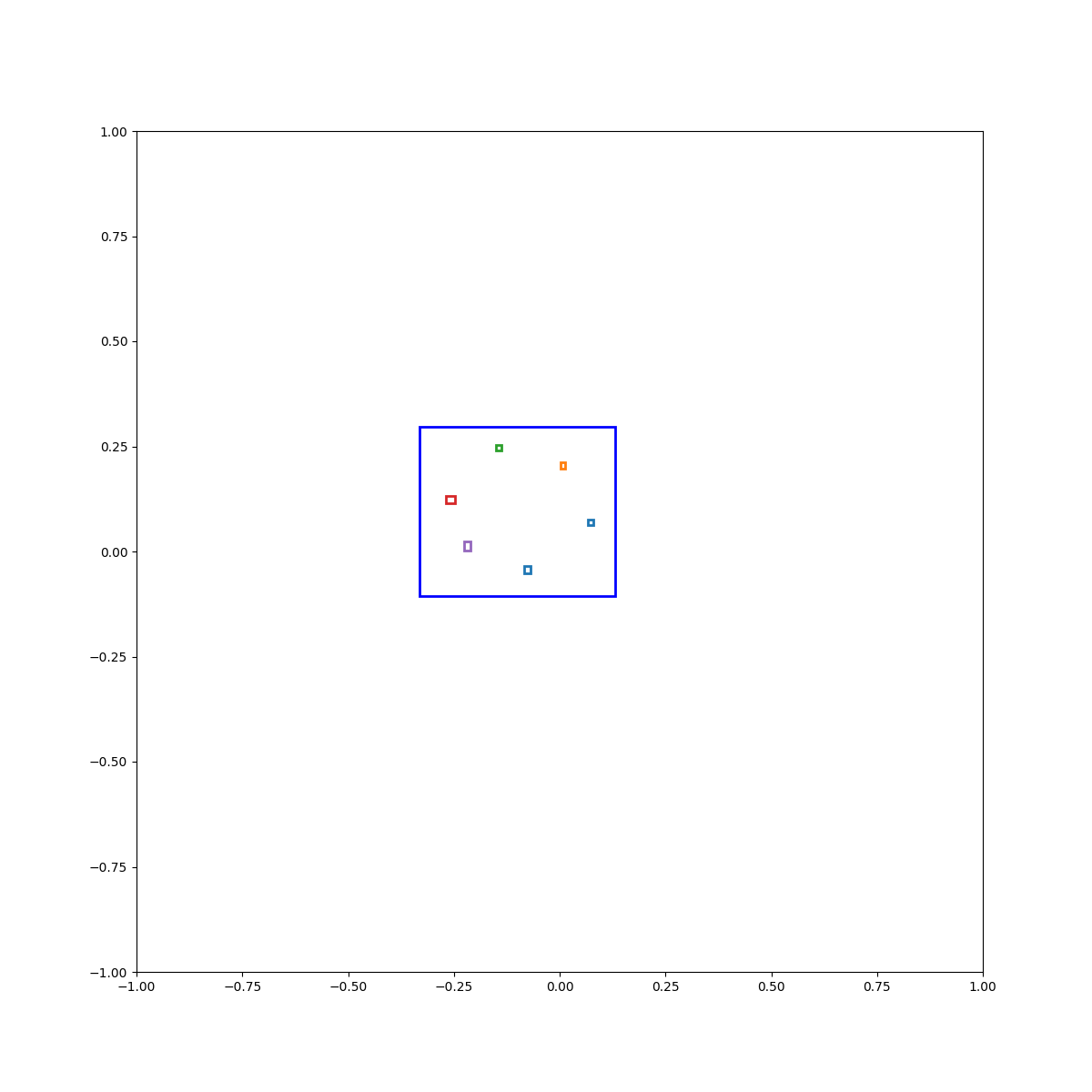
(Zero-Shot) Circle inside plate
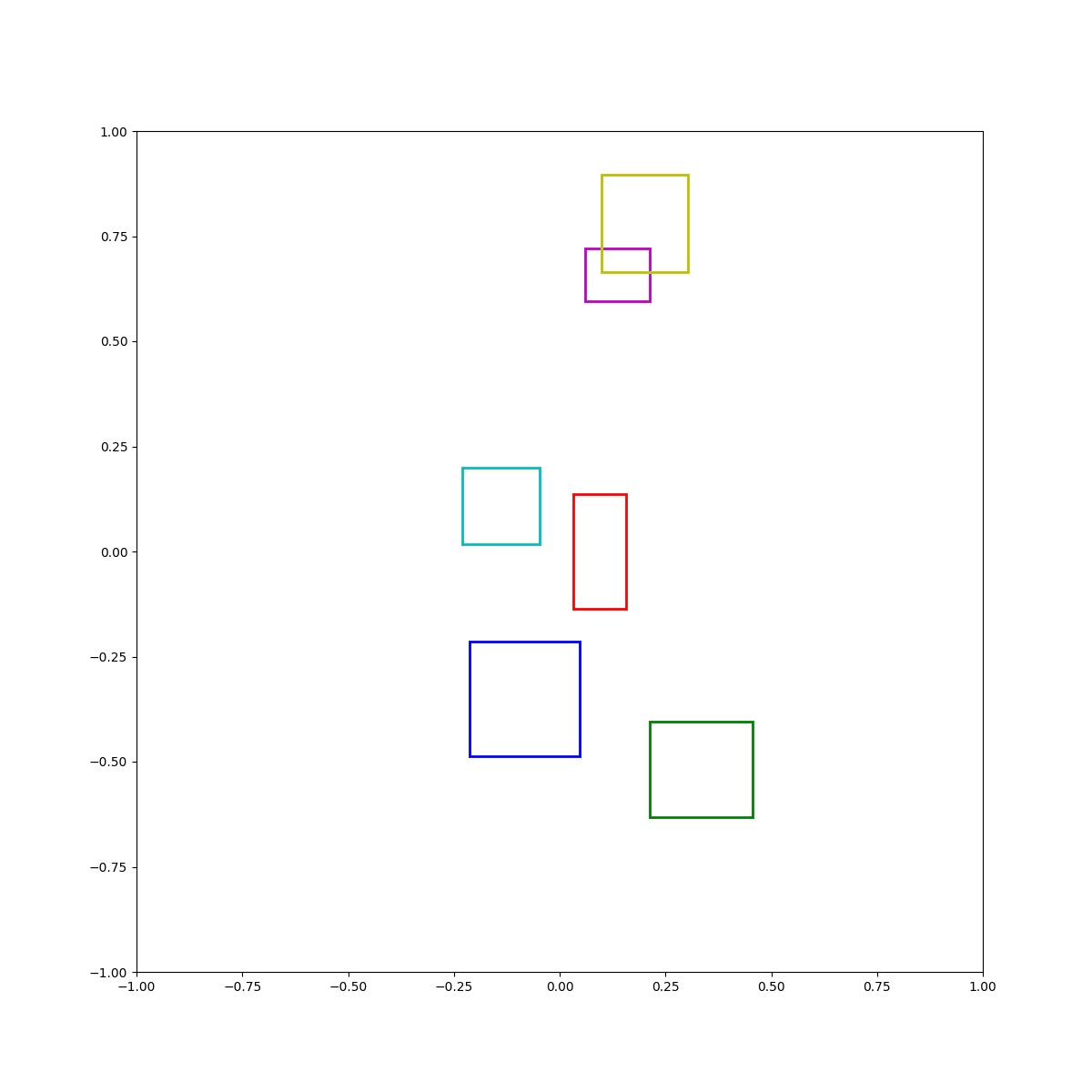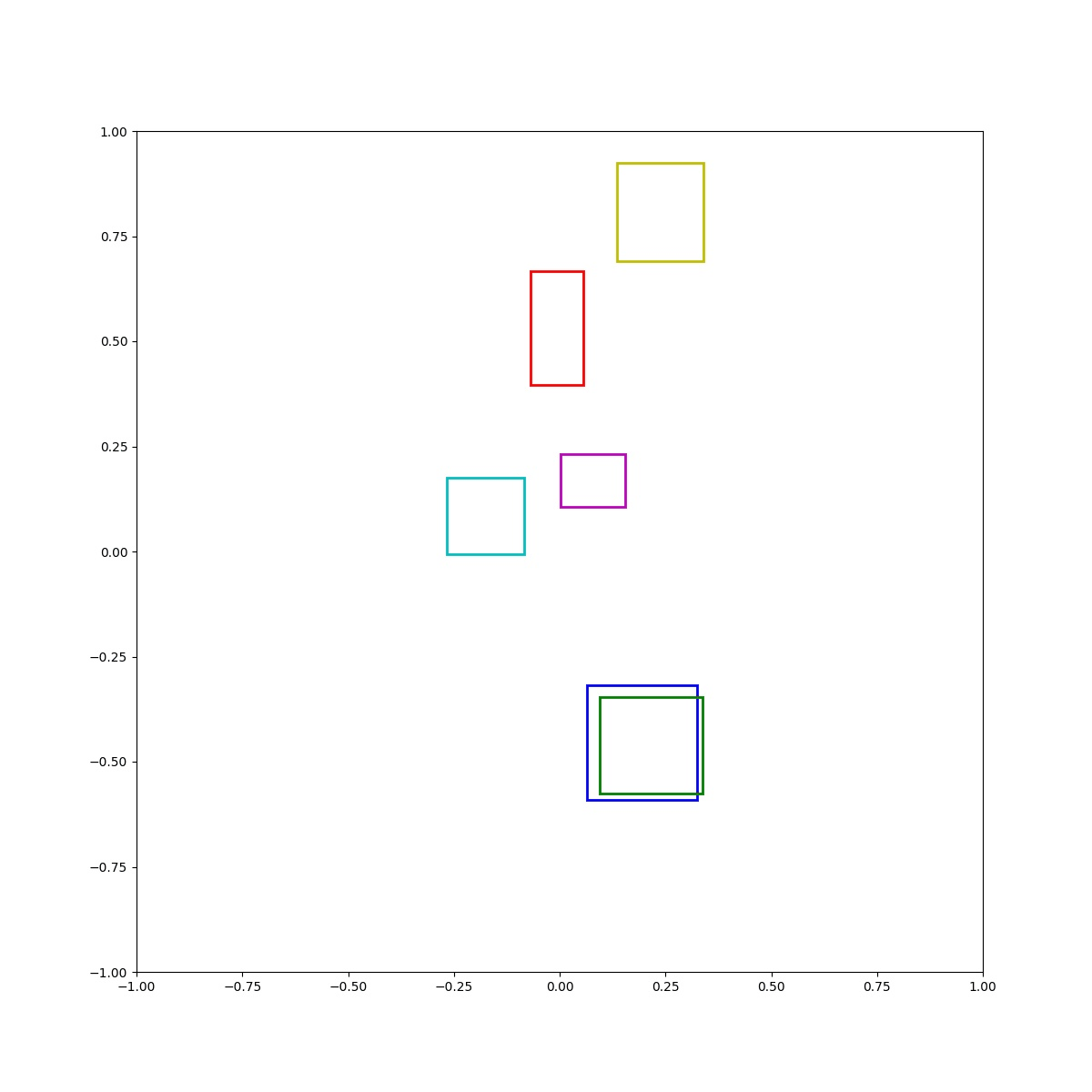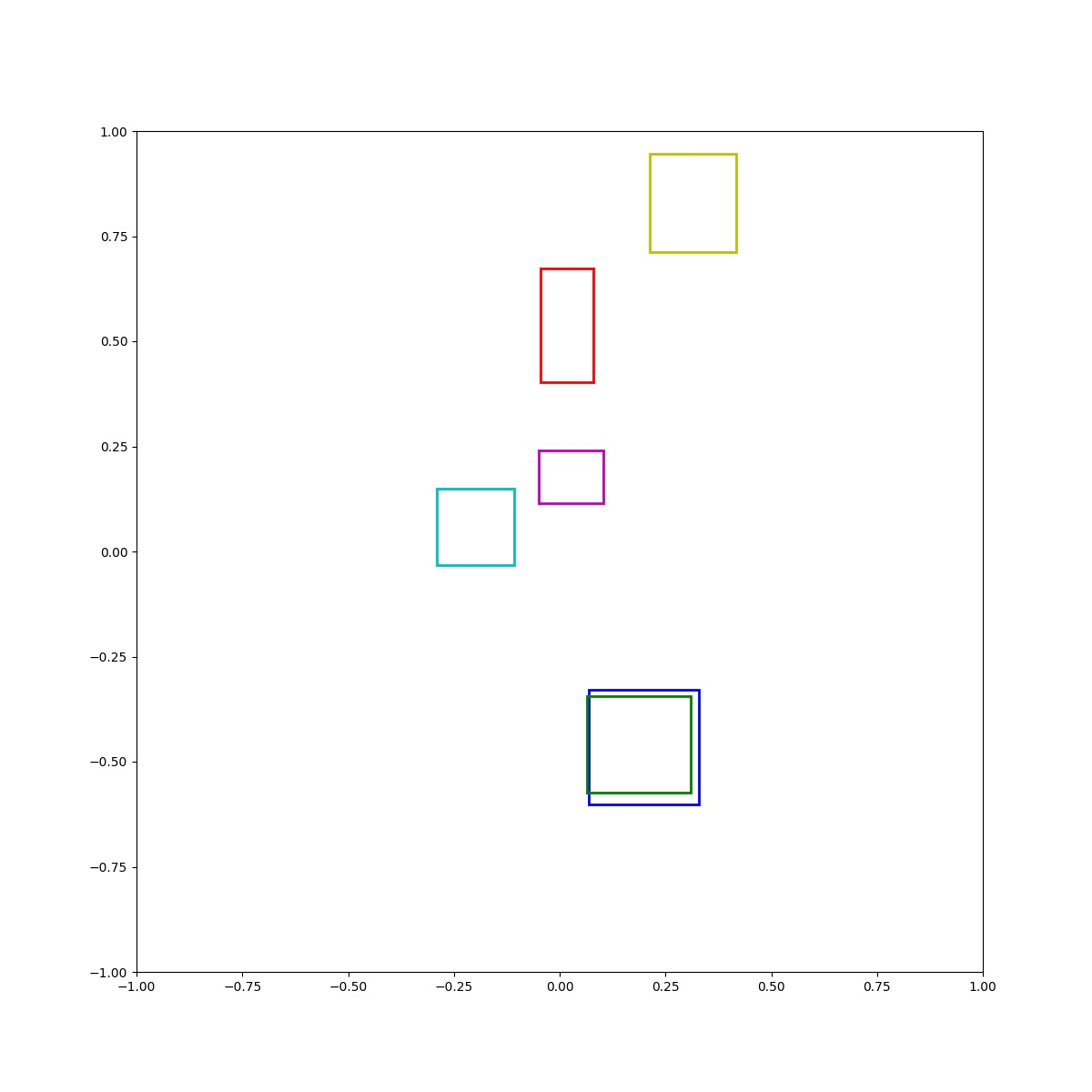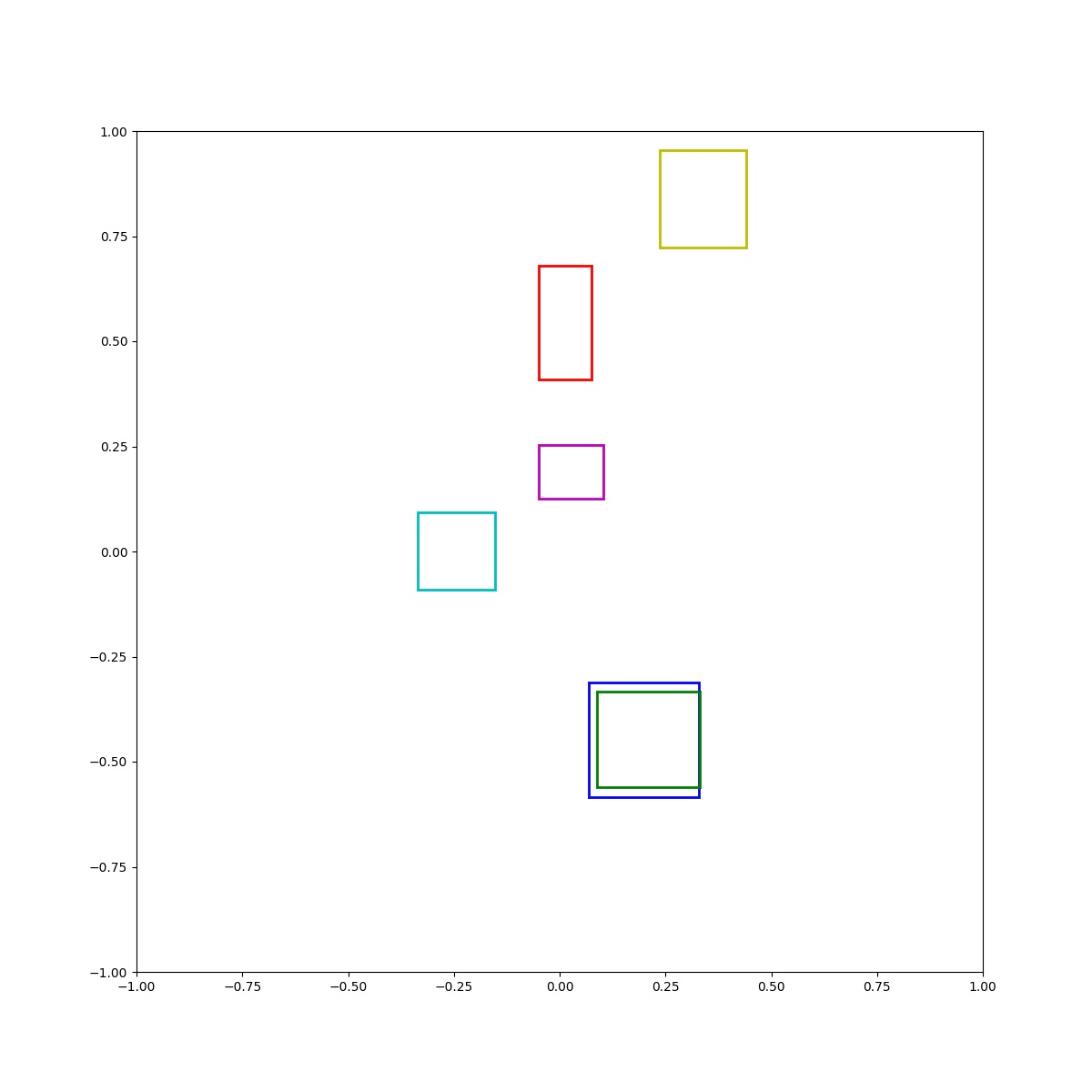
(Zero-Shot) Green inside blue and blue right of red and cyan left of blue and red above box and blue below yellow
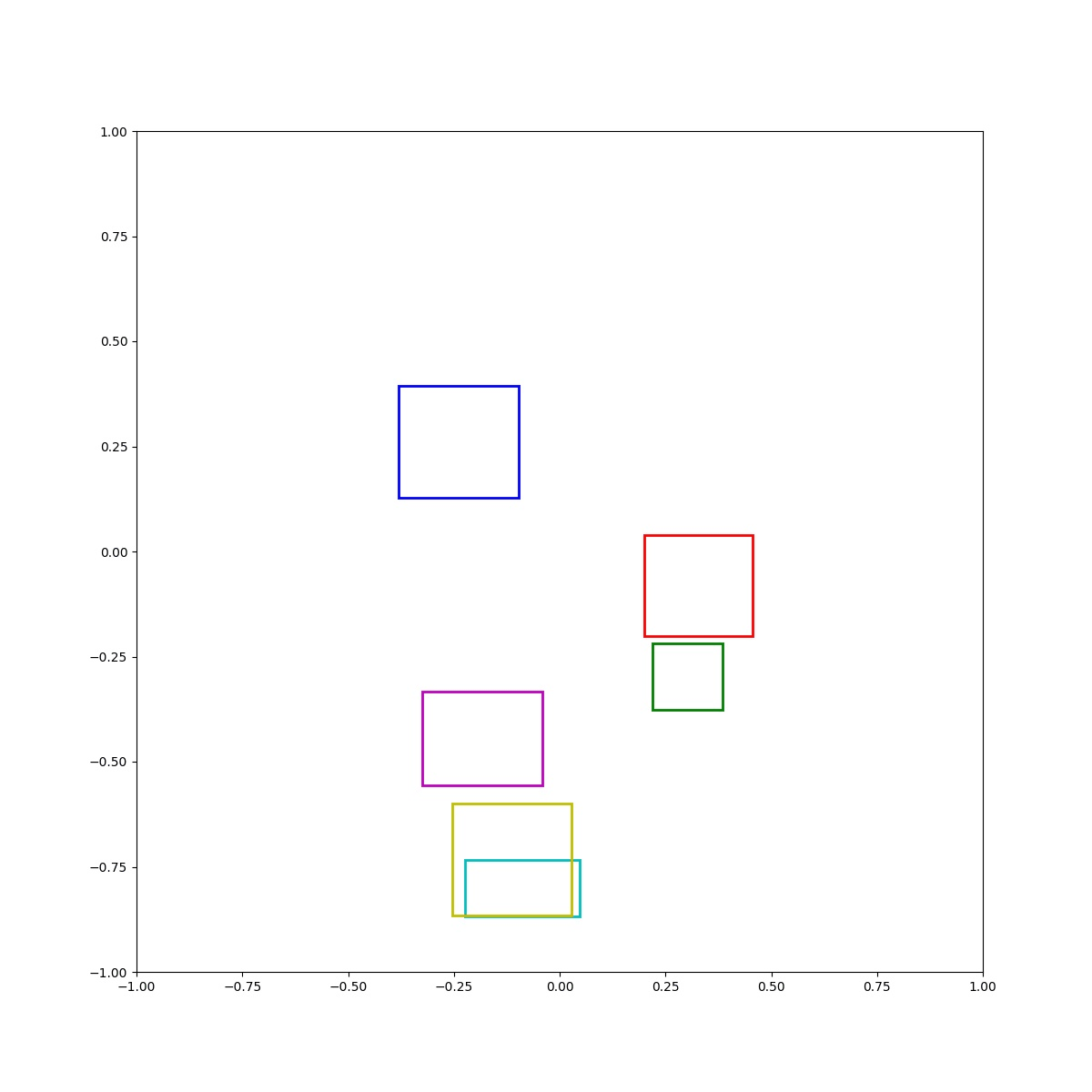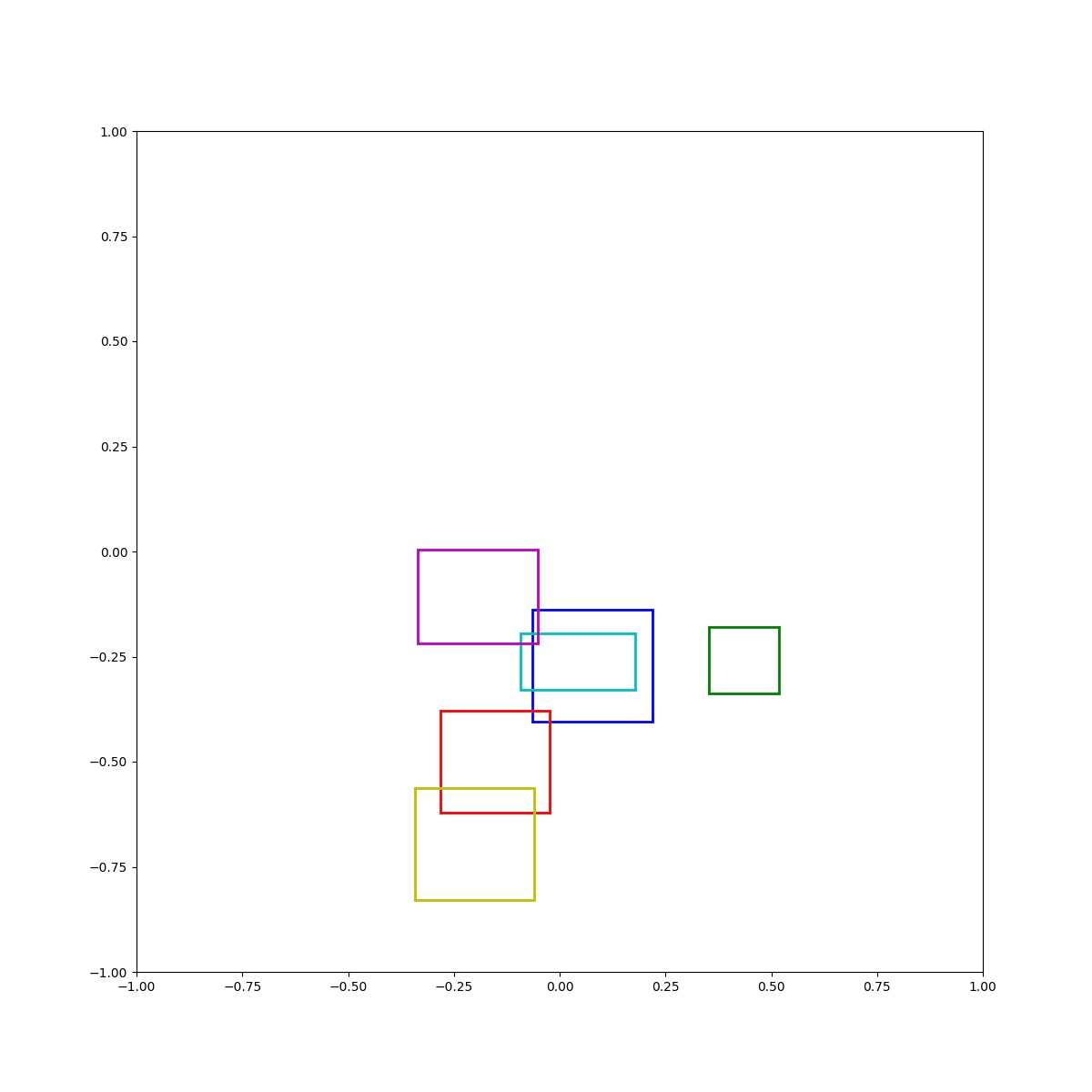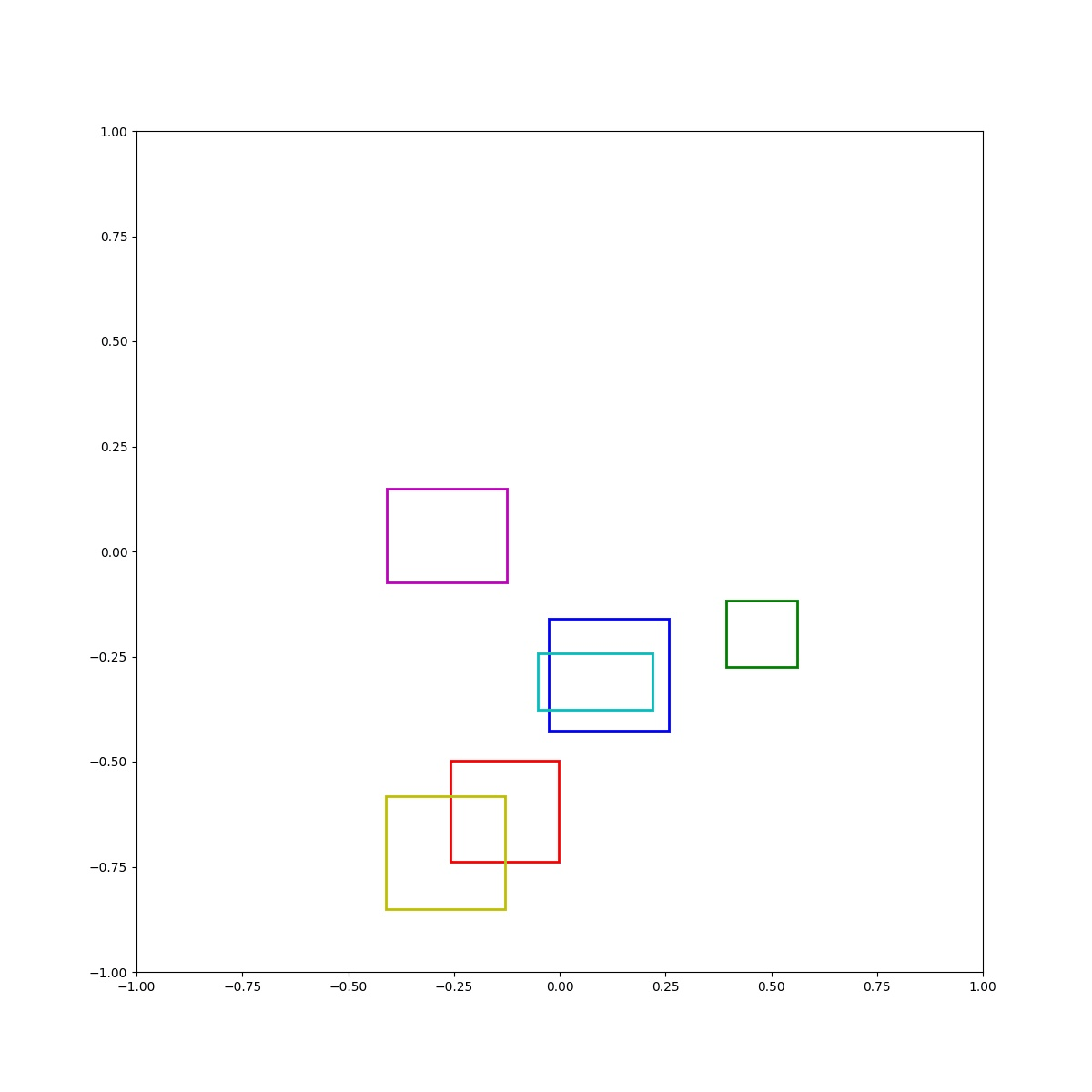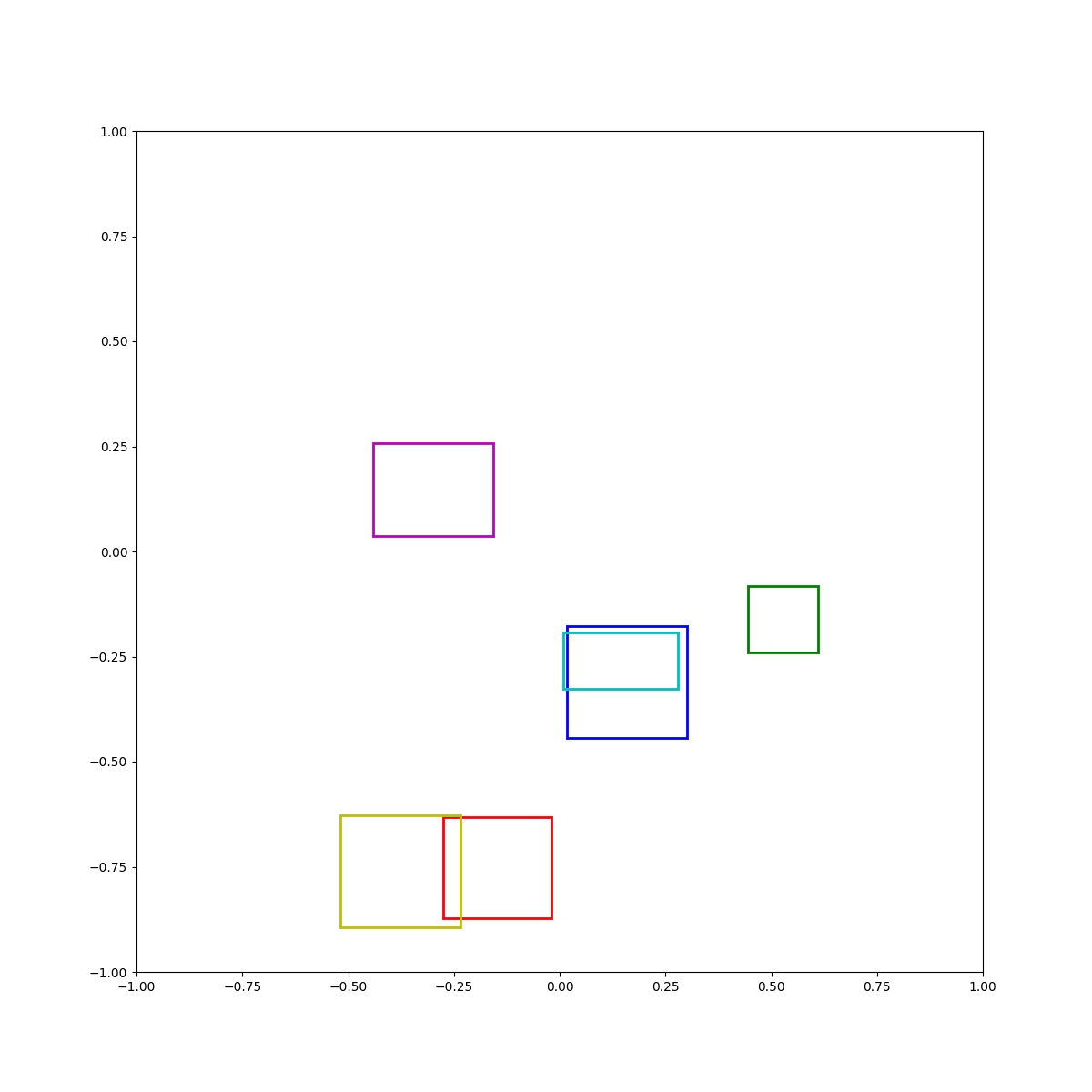
(Zero-Shot) Blue left of green and blue right of red and cyan inside blue and red below magenta and blue above yellow
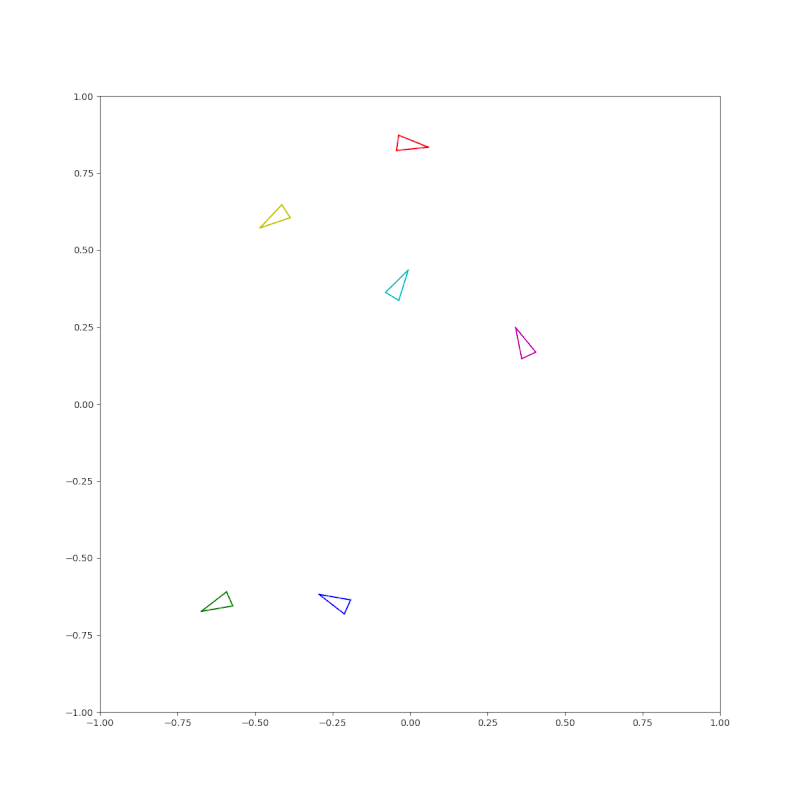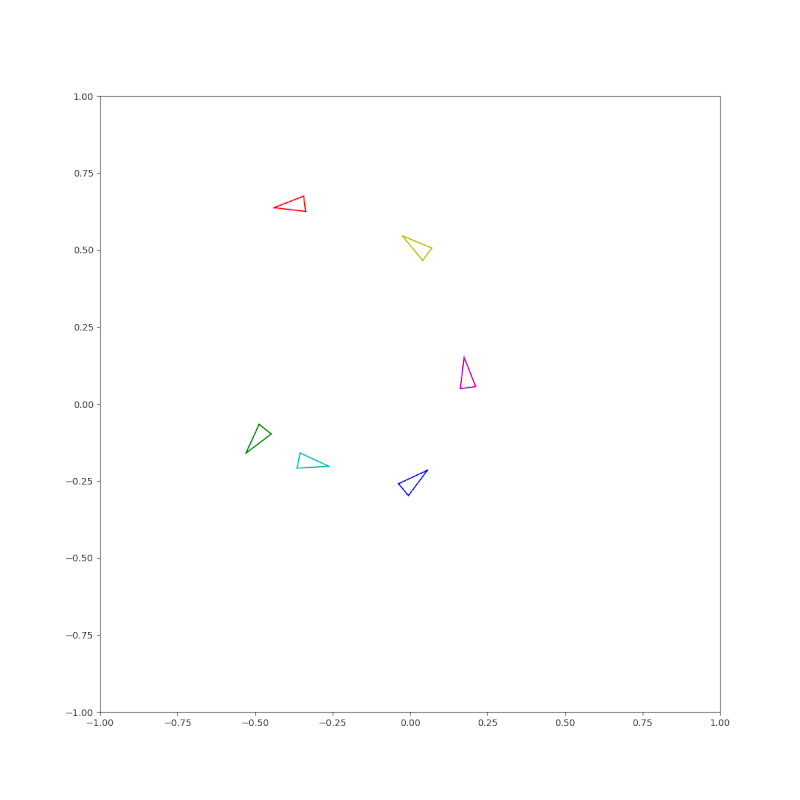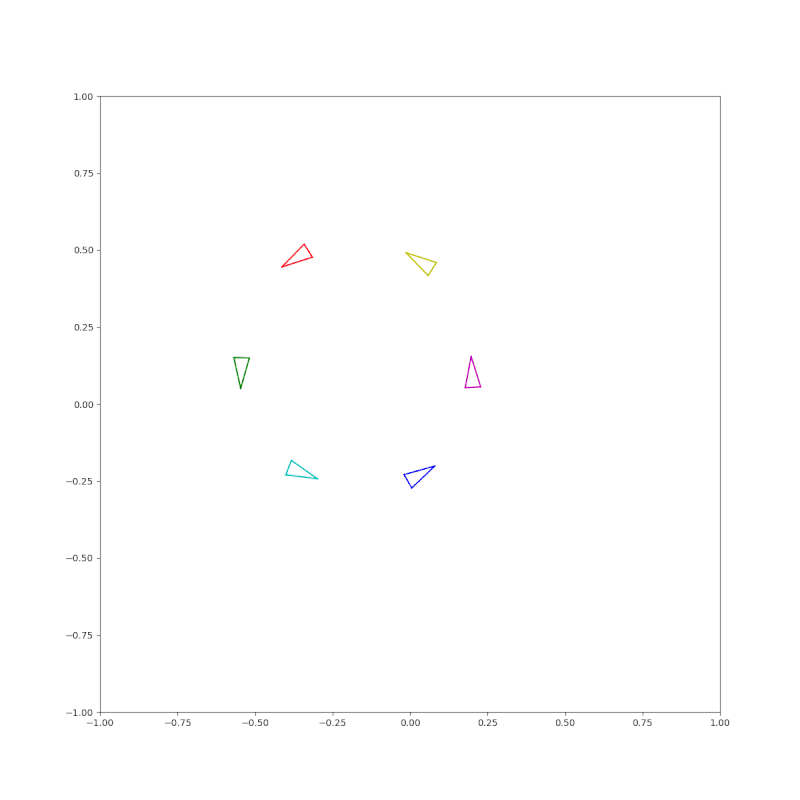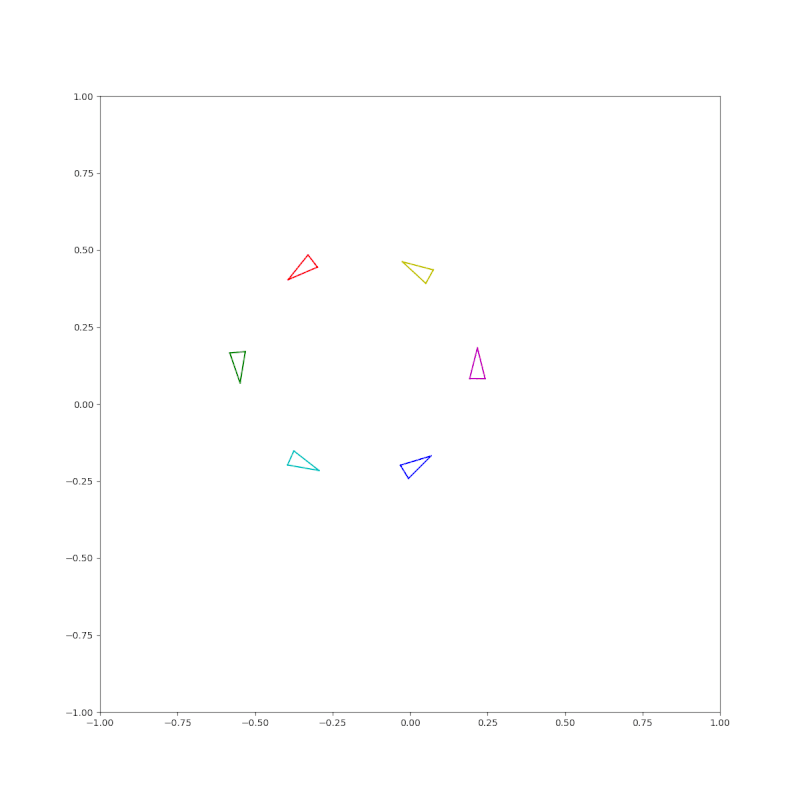
(Pose) A circle of triangles each pointing to the next

(3D) Red on top of green

(3D+Zero-Shot) Stack cyan on top of red on top of green on top of blue
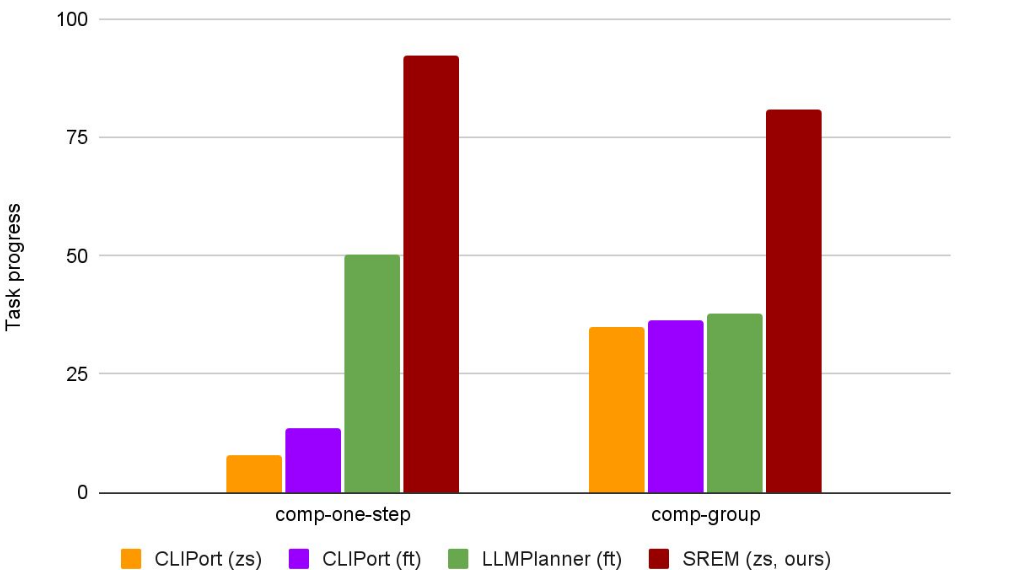
Quantitative Results
SREM outperforms state-of-the-art Large Language Model planners on highly compositional tasks.
Video
Paper and Bibtex

@inproceedings{gkanatsios2023energybased,
title={{Energy-based Models are Zero-Shot Planners for Compositional Scene Rearrangement}},
author={Gkanatsios, Nikolaos and Jain, Ayush and Xian, Zhou and Zhang, Yunchu and Atkeson, Christopher and Fragkiadaki, Katerina},
booktitle={Robotics: Science and Systems},
year={2023}
}
}